Объектно-ориентированное программирование
1. ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ
Расширение возможностей вычислительной техники и увеличение масштабных задач, решаемых с помощью ЭВМ, приводят к возрастанию размера и сложности систем программного обеспечения. Если еще два-три десятилетия назад составление программ для ЭВМ являлось в значительной мере искусством, которым владели немногие, то в наши дни разработка программного обеспечения вычислительных систем проводится большими коллективами и затраты на его создание значительно превышают затраты на аппаратную часть. В такой ситуации становится весьма актуальной проблема снижения стоимости программного обеспечения, решение которой связано с поиском новых эффективных путей и методов разработки программ. Последним достижением в этой области и является Объектно-Ориентированное Программирование.
Немного истории. В конце сороковых - начале пятидесятых годов ошибки программирования не представляли серьезной проблемы. Они объяснялись отсутствием опыта при использовании новой техники. При этом надо сказать, что в эти годы техника бурно развивалась, и программное обеспечение постоянно шло вслед за техникой.
Однако ни в шестидесятых, ни в семидесятые годы положение в программировании не изменялось существенно, хотя и возникли такие супер языки, как АЛГОЛ и ФОРТРАН. Но, эти годы не прошли даром, через ошибки были найдены верные подходы, которые и реализуются в настоящее время.
Интересный пример, в 1964 году фирма IBM приступила к разработке операционной среды OS. Трудозатраты на ее разработку доводки к защите оценивались в 5000 человеко-лет! Хотя среда была сдана через три года.
Методы разработки программного обеспечения являют собой некоторую синтезированную дисциплину, в которой для составления алгоритмов используются математические методы, для оценки затрат и выбора компромиссных решений - методы инженерных расчетов, а для определения требований к системе, учета ситуаций, связанных с различными потерями, организации работы исполнителей и прогнозирования-методы управления.
Для того чтобы лучше увидеть преимущества и некоторые недостатки ООП расскажем об этапах разработки программного обеспечения.
Цикл (цикл жизни) разработки программного обеспечения делится на 6 частей, которые приведены ниже вместе с временными затратами на реализацию каждого из этапов цикла:
1) анализ требований, предъявляемых к системе- 10%;
2) определение спецификаций- 15%;
3) проектирование- 20%;
4) кодирование- 20%;
5) тестирование- 20%;
6) эксплуатация и сопровождение- 25%.
Каждая программа, входящая в систему, должна отвечать таким требованиям, как ПРАВИЛЬНОСТЬ, ТОЧНОСТЬ, СОВМЕСТИМОСТЬ, НАДЕЖНОСТЬ, УНИВЕРСАЛЬНОСТЬ, ПОЛЕЗНОСТЬ, ЭФФЕКТИВНОСТЬ, ПРОВЕРЯЕМОСТЬ и АДАПТИРУЕМОСТЬ. Все эти требования максимальны и верны уже на протяжении двух десятилетий, и не потеряли своей значимости для программ ООП.
Итак, будем считать, что программа является:
· ПОЛЕЗНОЙ - если она функционирует в соответствии с техническим заданием, поставленным составленным в четкой форме, позволяющей однозначно судить о том, действительно ли программа отвечает перечисленным в нем требованиям.
· ТОЧНОЙ - если ее числовые данные или графические средства имеют допустимые отклонения от аналогичных результатов, полученных с помощью идеальных математических зависимостей.
· СОВМЕСТИМОЙ - если она работает должным образом не только автономно, но и как составная часть всей программной системы, и в других системах.
· НАДЕЖНОЙ - если она при всех условиях обеспечивает полную повторяемость результатов. Здесь, однако, срабатывает известная поговорка, что в любой даже маленькой, а тем более в гигантской программе существует как минимум еще одна ошибка.
· УНИВЕРСАЛЬНОСТЬ - если она правильно работает при любых допустимых вероятных исходных данных.
В ходе разработки программ должны предусматриваться специальные средства защиты от ввода неправильных данных, обеспечивающие целостность системы.
· ЗАЩИЩЕННОСТЬ - если она сохраняет работоспособность при возникновении сбоев. Это качество особенно для программ, предназначенных для решения задач в режиме реального времени, с большим временем выполнения или программ, осуществляющих обработку постоянно хранимых файлов.
· ЭФФЕКТИВНОСТЬ - если объем требуемых для ее работы ресурсов ЭВМ не превышает допустимого предела и максимально эффективно использует возможности ЭВМ.
· ПРОВЕРЯЕМОСТЬ - если ее качества могут быть продемонстрированы на практике. Здесь подразумевается возможность проверки таких свойств программы как, правильность и универсальность. Можно применить формальные математические методы, позволяющее установить, действительно ли программа удовлетворяет техническим условиям и выдает достаточно точные результаты.
· АДАПТИРУЕМОСТЬ - если она допускает быструю модификацию с целью приспособления к изменяющимся условиям функционирования. Адаптируемость в значительной степени зависит от конструкции программы, от того, насколько квалифицированно она составлена и полно снабжена документацией.
Создаваемая программа неотделима от вычислительной среды, с которой она взаимодействует. Она использует системные программные средства, а те в свою очередь могут пользоваться ее информацией. Программа либо сама создает файлы и обрабатывает их, либо делает это при помощи унифицированных системных программ. Поэтому процессы разработки программы в значительной степени зависят от наличия специализированных языков проектирования, каталогов данных, компиляторов, генераторов и др. Таким языком, или уже выше - средой стало ООП. При помощи ООП можно проще создать хорошую программу, располагая эффективными вспомогательными средствами операционной среды WINDOWS или же другой среды.
1.1. Зачем нужно ООП?
ООП как полностью разработанная концепция программирования возникла не вдруг. Идея использования программных «объектов» развивалась в течение многих лет разными коллективами. Были созданы системы исследовательского назначения, убедительно демонстрирующие такие достоинства ООП, как многозначность использования и расширяемость программных кодов. Однако при всей привлекательности, ряд особенностей ООП препятствовал его широкому внедрению. Системы ООП обычно отличаются громоздкостью и невысоким быстродействием, что в большей мере определялось чисто техническими проблемами. Также особенностью таких систем было использование специализированных языков, которые сильно отличаются от популярных FORTRAN, PASCAL и С.
С появлением TURBO PASCAL и C++ эти барьеры устраняются, и пользователи получают в свое распоряжение ООП в рамках широко распространенных языков, для мощных машин, ориентированных на промышленное производство высокоэффективных программ. Эти системы генерируют быстродействующие программные коды, которые можно использовать непосредственно в системных и прикладных программах. Устранение этих препятствий дает возможность программистам воспользоваться всеми достоинствами ООП и дать пользователям новое поколение прикладных программ.
1.2. Парадигмы программирования
В программировании существуют различные парадигмы, представляющие собой разные подходы к написанию программ. Большинство программистов знакомы лишь с немногими из них, это визуальное и процедурное программирование, однако существует программирование, основанное на логическом, параллельном программировании, программировании потоков данных, программирование реального времени и др. Объектно-ориентированный подход вбирает в себя различные преимущества многих их парадигм программирования.
Такое количество парадигм связано с огромным количеством разнообразных научных и технических задач, а также все новыми видами компьютерных систем.
Общая архитектура компьютеров позволяет с большей или меньшей мерой эффективности моделировать одну архитектуру с помощью другой. Из архитектур наиболее удачны те, в которых за счет аппаратуры и программного обеспечения достигнута наивысшая скорость и простота использования.
1.3. Объектно-ориентированный подход
Если Вы зададите вопрос: ‘Что такое ООП?’ то в ответ услышите много определений, и во всех из них этот термин употребляется не в его точном смысле. Даже в тех случаях, когда вопрос касается не конкретных продуктов или инструментов, акцент опять-таки будет поставлен по-разному, в зависимости от того, какие именно стороны ООП собеседник считает наиболее полезными и интересными. Получается, что каждый пользователь дает свое собственное определение, в зависимости от конкретной задачи решаемой им.
Прежде чем дать определение ООП со стороны, включающее истинные позиции ООП в мире программирования, необходимо устранить всякую путаницу в терминологии. Это необходимо, поскольку термин « Объектно-ориентированный» используется, по крайней мере, еще в одном смысле, а именно для обозначения специального типа прикладных графических программ. Этот термин в последнем случае служит для противопоставления пиксел-ориентированных графических программ. Объектно-ориентированная графика предполагает, что полная картина складывается из нескольких самостоятельных объектов, над каждым из которых всегда можно выполнить отдельные преобразования. Здесь и далее, мы будем понимать под понятием Объектно-ориентированный только лишь стиль программирования и инструмент. При этом верно также, что с помощью объектно-ориентированной техники программирования удобно создавать графические программы выше сказанного типа. Впрочем, ООП не является панацеей, и программы могут быть созданы без средств ООП. Но это может сказаться на увеличении времени кодирования, тестирования и др.
Теперь подойдем к определению ООП:
ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ - это способ программирования, обеспечивающий модульность программ за счет разделения памяти на области, содержащие данные и процедуры.
Области могут использоваться в качестве образцов, с которых по требованию могут делаться копии.
В соответствии с этим определением объект понимается как участок памяти. Наиболее важен способ разделения памяти компьютера, позволяющий каждому из модулей или объектов функционировать относительно друг друга независимо. Такое разделение памяти обладает многочисленными преимуществами при программировании. Каков смысл в словах ‘ разделение памяти ‘? Это означает, что имеется система разбиения памяти компьютера на функционально относительно независимые области. Эти области независимы в том смысле, что могут использоваться в разных программах без модификации с полной уверенностью, что ни одна из них не будет занята при включении ее в другое окружение.
В нашем определении сказано, что в выделенных областях размещается не только данные, но и код выполняемых процедур. Это разделение существенно для защиты объектов. Если бы этого не было, т.е. доступа к памяти объекта, то с его данными могли бы происходить непредсказуемые события, что сказалось бы на выполнении функций. По этой причине активные процессы ОО системы оформляются как локальные функции и процедуры. Они, и только они, имеют доступ к данным объекта. Таким образом, объект защищает себя от разрушения данных в результате внешних событий. В результате, как только функциональный элемент программы написан и полностью отлажен, он становится работоспособным независимо от последующих дополнений и модификаций в использующей его программе.
Каждая парадигма программирования имеет свои метафоры, помогающие программисту думать о структуре программы. Информатика полна метафор, постепенно переходящих программистский жаргон. Двумя яркими примерами могут служить термины ‘ память ’ и ’ окно ’. С другой стороны эти слова достаточно далеки от реальных объектов.
Отметим, что и ООП имеет метафоры, к ним можно отнести ‘ наследование ’, ‘ классы ’, ‘ передача сообщений ’.
ООП нельзя рассматривать как абсолютно новое, не имеющее прецедентов направления в программировании.
Оно просто вобрало в себя последние достижения в области языков программирования, делая новый шаг в сторону ясности, модульности и эффективности. С некоторой точки зрения, ООП можно рассматривать, как попытку довести идеи структурного программирования до логического завершения.
В структурном программировании переменные могут быть локализованы в процедурах, передающих друг другу в качестве аргументов строки и числа. ООП делает здесь небольшой шаг вперед. Переменные теперь локализуются не только в процедурах. Основным строительным блоком становятся объекты, т.е. защищенные области памяти, которые могут содержать как локальные данные, так и локальные процедуры. Более того, строительные блоки не взаимодействуют друг с другом посредством передачи параметров. Локализованные в объектах процедуры, обычно называемые методами, служат сообщениями, которые посылают и принимают объекты. В этом отношении объекты напоминают маленькие компьютеры, находящиеся внутри основного компьютера, каждый из которых обладает своими областями данных и кода.
В большинстве ОО систем имеются два разных типа объектов: классы и экземпляры. Классы могут быть логически связаны друг с другом. При этом один из них называется подклассом, а другой суперклассом. В целом, суперкласс - это более абстрактный класс, а подкласс более конкретный. Так, например, мы можем создать класс мебель, а затем класс шкаф как подкласс класса мебель и книжный шкаф как подкласс класса шкаф. В этом примере класс мебель будет суперклассом для класса шкаф, а шкаф - суперклассом для класса книжный шкаф.
У ОО Систем имеются как минимум три преимущества: одно состоит в том, что если вы написали код для класса, то вы можете иметь столько экземпляров этого класса, сколько позволяет память. Класс - это просто образец, по которому строится каждый экземпляр, который, в свою очередь снабжается собственной областью памяти, недоступной для других объектов иначе, как посредством обращения к локальным методам этого объекта. Это, в частности, означает, что в ОО Системе могут совершенно свободно сосуществовать, не влияя друг на друга, произвольное количество таких объектов, как графические окна, редакторы, интерпретаторы, и т.д.
другое преимущество - представляется механизмом наследования. Подклассы автоматически получают все переменные и методы своих суперклассов. То есть более специализированные функции могут быть написаны за счет добавления частей, делающим их уникальными. При этом все остальные свойства будут унаследованы автоматически. Возможность иметь один и тот же интерфейс с широким спектром типов объектов составляет третье преимущество. Это достигается за счет того, что для методов разных объектов, имеющих разную реализацию, может использоваться одно и тоже имя. При этом различие в реализации остается невидимым пользователю. Например, мы можем создать несколько различных классов, соответствующих разным многогранникам. Затем в каждом из этих классов мы зададим методы, вычисляющие объем и площадь поверхности тела. Формулы и программная реализация могут отличаться, но имена, с помощью которых эти методы вызываются, будут одинаковы. К этим методам можно обратиться, написав для примера куб.объем, конус.объем. В каждом случае будет вызван требуемый метод, который вернет искомый объем.
Некоторые считают основой особенностью ООП возможность использовать один и тот же код в разных программах. Однако подобную возможность дают и библиотечные функции. Ключевые преимущества
ООП становятся очевидными не сразу, но опытные программисты, которые поработали с такими системами, подтвердят, что ОО языки значительно облегчают работу над большими программами. Это не проходит, однако, само собой. Ключ к успеху кроется в правильном разбиении программы на части. Одновременно необходимо изучать правильную технику кодирования и приемы, упрощающие работу членам команды программистов или же самому себе.
Границы ОО Систем обычно несколько различны. Части приложений разбросаны по большому количеству классов и подклассов. Для эффективного программирования в таких системах важно иметь адекватные инструменты и эффективные методы поддержания целостности и правильной организации приложения.
Важно отметить, что ООП не следует рассматривать как нечто, что можно освоить в один момент.
Дело в том, что парадигма ООП существенно отличается от всего того, к чему привыкли программисты. Итак, кратко изложим в резюме основные четыре преимущества ООП:
1) Стандартные соглашения вызова для широкого диапазона операций, реализующих различные модификации одной темы.
2) Возможность управлять очень большими программными проектами, разбивая большие задачи на небольшие, независимые и легко образуемые части.
3) По-настоящему модульное программное окружение, сводящее повторы при кодировании к минимуму.
4) Возможность порождать множество экземпляров функции или объекта, используя один и тот же код. Разные экземпляры не оказывают влияние друг на друга.
При создании любого типа программы возникают следующие вопросы, на которые программисту необходимо делать соответствующие выводы. Неучет одного из пунктов затягивает время разработки:
1) Общая характеристика программы - в достаточной степени подробная, чтобы пользователь мог понять отвечает ли программа требованиям или нет.
2) Функции системы - приводятся основные блоки (процедуры) программы и типы входных и выходных данных.
3) Сфера применения - обозначается круг пользователей знающие программирование или чайники.
4) Сбор, корректировка и проверка данных - рассматриваются источники данных, поступающих в программу. Принимается решение о корректировке и проверки данных. Если входные данные соответствуют требованиям вашей программы, то коррекция может отсутствовать.
5) Отчет - описываются формы, периодичность и общее содержание отчетов, выдаваемых программой.
6) Вычислительная среда - определяется минимальный состав технических средств необходимых для нормального функционирования системы (если такая возможность есть).
7) Технические средства - подбирается необходимая конфигурация технических средств, например, объем оперативной памяти, требования к внешним устройствам (если есть возможность).
8) Программные средства - подбирается тип операционной среды, программы, библиотеки.
9) Связь с внешней средой - как пользователь взаимодействует с программой.
10) Режимы работы - возможность работы в условиях интерактивного режима или режима реального времени или их комбинаций.
11) Вход системы - определяются форматы входных данных всех типов, вводимых пользователем, а также внутренняя структура данных.
12) Выход системы - описываются форматы выходных данных.
13) Управляющие параметры - перечисляются параметры, задаваемые при настройке системы на данную конфигурацию технических и программных средств.
14) Рабочие инструкции - делается общий обзор содержания инструкций, касающихся использования программы, ограничений на входные данные и др.
15) Соблюдение стандартов и общепринятых обозначений.
16) Универсальность программы - по возможности программа должна работать в различных программных средах и с любым типом входных данных и уровнем знания пользователя.
17) Надежность функционирования.
18) Защита информации.
19) Документация.
20) Спецификация программы и подпрограмм.
21) Организация данных.
Рассмотрим более подробно основные части ООП:
1. ЧТО ТАКОЕ ОБЪЕКТ - На самом верхнем уровне находится понятие объекта. В физическом лице объектом может быть что угодно: автомобиль, человек и другое. Объекты обладают свойствами, такими, как, например, цвет или размер. Они обнаруживают поведение, скажем, начинают функционировать или менять состояние в ответ на определенный набор внешних воздействий.
Объекты реального мира можно использовать многократно, их не нужно каждый раз создавать вновь. Так, значительную долю схемных компонентов на печатных платах электронных приборов составляют стандартные, недорогие, серийно изготавливаемые элементы. Существование таких элементов позволяет разработчику сосредоточиться на решении стоящей перед ним задачи вместо того, чтобы заново изобретать средство для ее решения.
Хотелось бы, чтобы так же были устроены и наши программы. Ведь сколько сил при программировании уходит на реализацию часто повторяющихся типовых задач - поиска, сортировки, чтения.
Теоретически, при проектировании “ сверху вниз “ должна обеспечиваться модульность, благодаря которой отдельные программные компоненты будут хорошо стыковаться друг с другом. На практике же эта стыковка редко получается локальной, и программные модули, полученные обычным способом, для своего повторного использования почти всегда требуют какой-либо модификации. ООП в корне меняет положение, снабжая программные объекты встроенными характеристиками, которые помогают справиться с все возрастающей сложностью разработки программного обеспечения. Три важнейшие характеристики объектной парадигмы - это:
ИНКАПСУЛЯЦИЯ (incapsulation)
НАСЛЕДОВАНИЕ (inheritance)
ПОЛИМОРФИЗМ (polymorphism)
1.4. Инкапсуляция
Имея в виду аналогично с существованием и взаимодействием объектов реального мира, можно смоделировать программные “объекты ” со своими свойствами и поведением. Понятие инкапсуляции означает, что в качестве единого целого, называемого объектом, рассматривается некоторая структура данных, определяющая его свойства, или атрибуты, и некоторая группа функций.
В Borland C++ свойства объектов хранятся в структурах данных, напоминающих обычные структуры С++, а поведение объектов реализуется в виде функций, называемых “функции- члены ”(member functions).
Borland C++ предоставляет программисту широкие возможности в области управления доступом к атрибутам объектов и их функциям-членам. Например, если какие-либо атрибуты и функции объекта объявлены приватными, то к ним нет доступа извне, за исключением функций, объявленных дружественными (friends) данному объекту. Атрибуты и функции, объявленные общими, доступны любому внешнему объекту, а к тем, которые объявлены защищенными, доступ имеют лишь некоторые из остальных объектов. Эта особенность ООП называется ограничением доступа (data liding); она позволяет делать данные “невидимыми ”, а за счет этого добиваться, чтобы все манипуляции с данными выполнялись только через общие функции- члены.
Ограничение доступа повышает надежность и модифицируемость программ, ослабляя взаимозависимость между объектами.
Фактически, если общие функции- члены описаны корректно, то приватные структуры данных и функции-члены объекта можно изменять, не затрагивая программную реализацию других объектов. Этот ограниченный доступ к информации аналогичен тому, что мы наблюдаем с объектами реального мира, где часто нет способа (и обычно нет необходимости) узнать во всех подробностях внутреннее устройство какого-либо объекта, например, телефонного аппарата.
1.5. Наследование
НАСЛЕДОВАНИЕ - пожалуй, самая впечатляющая особенность ООП. Оно позволяет одним объектам приобретать атрибуты и поведение других объектов. Наследование помогает сделать разработку более экономной и обозримой, так как объекты пользуются одними и теми же атрибутами и формами поведения без дублирования реализующих их программных кодов.
Хорошей аналогией здесь может служить таксономная схема, которой пользуются зоологи и ботаники для классификации живых организмов. По этой схеме растительные и животные царства делятся на группы, так называемые типы. Каждый тип, в свою очередь, делится на классы, отряды, семейства и т. д. Группы более низкого уровня наследуют (разделяют) характеристики групп более высоких уровней. Так, из утверждения о том, что волк относится к семейству псовых, вытекает сразу же несколько положений. Из него следует, что у волков хорошо развиты слух и обоняние, поскольку таковы характеристики псовых. Так как псовые входят в отряд хищных, это утверждение говорит еще о том, что волки питаются мясом. Поскольку хищные относятся к млекопитающим, это утверждение говорит о том, что волки имеют волосяной покров и регулируемую температуру тела. Наконец, так как млекопитающие являются позвоночными, мы узнаем и то, что у волков есть позвоночник.
Программные объекты выстраиваются в иерархию примерно таким же образом. Например, можно мысленно создать или абстрагировать объект высокого уровня - Окно. Для этого заметим, что любое окно на экране компьютера имеет определенное положение по координатам Х и У, а также высоту, ширину, стиль рамки и цвет фона.
Если рассматривать меню, то можно отметить, что объект МЕНЮ обладает всеми свойствами ОКНА, но вдобавок имеет и ряд собственных - например, строки позиций меню и, возможно, линейку прокрутки. Ниже ОКНА можно было бы поместить и РЕДАКТОР, обладающий всеми характеристиками окна и, кроме того, способностью принимать символы с клавиатуры и манипулировать ими.
Заметим, что как МЕНЮ, так и РЕДАКТОР можно с полным правом называть ОКНАМИ, так как оба они имеют ширину, высоту и т. д., но при этом они различаются между собой по виду и способу функционирования.
Такая иерархия объектов может иметь много уровней. К примеру, при дальнейшей конкретизации объекта РЕДАКТОР мы могли бы ввести нечто под названием ПОЛЕ приглашения, которое наследует все черты РЕДАКТОРА, но ограничено одной строкой текста, перед которой стоит целая цепочка символов, образующих приглашение.
По терминологии ООП языка С++, ОКНО, МЕНЮ, РЕДАКТОР и ПОЛЕ приглашения - это классы. Классы образуют иерархию, которая определяет наследование отношений между ними. Так как класс МЕНЮ наследует свойства класса ОКНО, то в языке Borland C ++ МЕНЮ называется производным классом ОКНА. В свою очередь, ОКНО является по отношению к МЕНЮ базовым классом.
Важно отметить, что сами по себе классы - это не объекты, а шаблоны для создания объектов. Когда нужно, создается экземпляр класса (его обычно называют просто объектом), который и используется. Отношение между классом и экземпляром класса такое же, как и между типом данных и переменной.
В нашем примере мы рассматривали атрибуты ОКНА и его производных классов, но, как вы помните, было сказано, что объекты наследуют и поведение. Эта характеристика наследования имеет ряд важных последствий для проектирования программ.
Создавая класс ОКНО, мы, конечно, предусмотрим функцию- член, позволяющую перемещать окно по экрану. МЕНЮ унаследует эту функцию от ОКНА, а это значит, что любое меню можно тоже перемещать по экрану, не программируя заново эту функцию. Объекты меню используют для этого тот же программный код, что и обеты окна.
Это свойство, называемое многократностью использования кода, не только позволяет избежать ненужного дублирования программных кодов, но и гарантирует, что коль скоро функция запрограммирована корректно, она будет правильно работать со всеми объектами, входящими в иерархию. Иначе говоря, как только вы напишите функцию- член, которая правильно перемещает по экрану ОКНО , объекты всех классов, производных от ОКНА, тоже станут перемещаться правильно.
Кроме того, все такие объекты будут двигаться по экрану одинаково, а это большое преимущество для пользователя: весь создаваемый пакет в целом станет более согласованным и лучше связанным. Это результат того, что любой функциональный элемент программируется только один раз на надлежащем уровне иерархии объектов. После этого его функция распространяется вниз по иерархии ко всем объектам, где она требуется. В результате все меню выглядят похоже, линейки прокрутки работают одинаково, где бы они не появлялись, а команды редактирования полей будут одни и те же для любых полей. Пакет уже не будет восприниматься как набор слабо связанных и несогласованных блоков, наспех прикрепленных друг к другу.
В некоторых ОО системах реализуется только одиночное наследование. То есть любой класс - скажем, МЕНЮ, может наследовать свойства только одного класса - например, ОКНА. В отличие от этого, Borland C++ расширяет иерархию, допуская множественное наследование так, чтобы МЕНЮ могло наследовать не только от ОКНА, но одновременно и от других классов. Возможность множественного наследования важна тем, что позволяет непосредственно комбинировать характеристики двух или нескольких различных классов, что уменьшает объем программ. Того же результата можно добиться и в системах с одиночным наследованием, но лишь ценой значительно больших усилий, так как для этого придется редактировать новые классы.
1.6. Полиморфизм и позднее связывание
Инкапсуляция и наследование - это две из трех основных характеристик, благодаря которым ООП является столь мощным методом.
Третья характеристика - это полиморфизм, который в сочетании с поздним связыванием представляет собой весьма продуктивную и сложную идею.
Термины “ раннее связывание” и “ позднее” относятся к этапу, на котором обращение к процедуре связывается с ее адресом. В случае раннего связывания адреса всех функций и процедур известны в тот момент, когда происходят компиляция и компоновка программы. Это позволяет приписать каждому обращению к процедуре соответствующий адрес. В большинстве традиционных языков, включая Си и Паскаль, используется только раннее связывание. В противоположность этому, в случае позднего связывания адрес процедуры не связывается с обращением к ней до этого момента, пока обращение не произойдет фактически, т. е. во время выполнения программы.
Вернемся ненадолго к нашему примеру с окнами. В такой динамической системе нельзя заранее предсказать, сколько окон будет на экране, и каких типов они будут (например, меню, редактор, и т.д.), и в какой последовательности пользователь будет с ними работать. В программе, где используется только раннее связывание, вся информация о количестве и типах окон хранится в основной программе. Все возможные действия пользователя над окнами тоже должны быть предусмотрены в этой программе. Каждый раз, когда пользователь производит какие-то действия с окном (будь то Редактор, Поле приглашения или что угодно), программа должна разобраться, что именно и с каким именно окном произошло, и вызвать соответствующие процедуры для выполнения надлежащих действий с этим окном. Таким образом, программе приходится отслеживать очень многое, она усложняется и теряет гибкость. Стоит добавить один новый тип окна или изменить поведение уже существующего, как придется корректировать программу во всех тех местах, где определяется, какие подпрограммы подлежат вызову.
Каким же образом можно улучшить положение с помощью позднего связывания? Рассмотрим случай, когда одно окно частично перекрывает другое. Если “ верхнее ” окно будет передвинуто или закрыто, то нижнее следует перерисовать для восстановления ранее перекрытой части.
Так как меню перерисовывается иначе, чем поле или редактор, то каждый объект в оконной иерархии должен знать, как перерисовать себя. Таким образом, в каждом классе будет своя функция - член, которая перерисовывает данный объект на экране. Следовательно, если требуется перерисовать объект, то программе не нужно анализировать, к какому типу окна он относится (как это требовалось при раннем связывании). Она просто вызывает функцию - член данного объекта ”ПЕРЕРИСОВКА ”. Объект исполняет эту свою функцию и корректно перерисовывает себя на экране.
Если пакет содержит семь типов окон, то в нем будет семь различных правил перерисовки, но все они будут называться одинаково “ПЕРЕРИСОВКА ”, но для каждого объекта это делается по-своему, так, как это нужно именно для него. Эта множественность форм, которые может принимать правило с одним и тем же именем, называется ПОЛИМОРФИЗМОМ, от греческого POLYMORPHOS - многообразный.
Полиморфизм - исключительно мощный метод обобщения однотипных задач для многих разных объектов. Он повышает степень абстрагирования при создании программного обеспечения, так как программист заботится только о том, как это действие выполнить. Возможен же полиморфизм благодаря позднему связыванию.
1.7. Расширяемость кода
Сочетание наследования и полиморфизма дает пользователям ОО программы замечательную возможность расширять эту программу, не имея ее исходного кода. Это можно делать, потому что наследование действует и после компиляции исходной программы. В терминах С++, если программист располагает описанием интерфейса с некоторым классом, он может определить произвольный класс, наследующий все свойства базового. После этого он может выборочно перегрузить (переопределить) поведение некоторых функций - членов так, как ему нужно. Это возможно даже в том случае, если базовый класс компилировался раньше, чем производный класс был написан или даже задуман. Поскольку позднее связывание происходит во время выполнения программы, изнутри объектного модуля вполне могут полиморфно вызываться функции, которых еще не существовало во время его компиляции.
Расширяемость позволяет выпускать на рынок или передавать другим пользователям библиотеки объектов без раскрытия алгоритмов или фирменных секретов, реализованных в объектах таких библиотек. Кроме того, если программный пакет создается с использованием библиотеки объектов, это не означает, что описания объектов должны браться только из библиотеки. Если один или несколько объектов в библиотеке не устраивают программиста, они могут быть модифицированы, и их расширения станут новыми классами.
Итак, подведем итог, дав краткое определение понятий ОО Программирования:
1) Центральным понятием ООП является класс
(class).
2) Объект - имеет уникальный набор переменных, который соответствует по имени и типу элементам данных, определенных для его класса.
3) Указатель (pointer) на объект обеспечивает косвенный способ доступа к объектам. Определив набор классов и операций, мы можем понять, что конкретно делает данная программа.
4) Инкапсуляция - объединение в одном элементе и данных, и процедуры их обработки. Именно инкапсуляция делает ООП привлекательным для программистов, так как мы можем определить данные, входящие в классы, и действия, которые могут выполняться над этими данными, как некоторую структуру - объект в системе, работающей согласно набору правил, или определить объекты, соответствующие фреймам, и обращаться к ним в программе как к объекту.
5) Наследование - следующий основополагающий принцип ООП, так это сохранение, перенос атрибутов данных и выполняемых над ними операций от объекта к объекту. С помощью этого принципа строятся различные иерархии классов (простое наследование), а также смешанные классы (множественное наследование), когда некоторый новый класс одновременно наследует атрибуты и выполняемые над ним операции от нескольких базовых классов. При этом имеется возможность модифицировать поведение объектов.
6) Полиморфизм - означает возможность единообразного обращения к объектам в тексте программы при сохранении уникальности поведения объектов.
Этот принцип позволяет определять целый ряд объектов на основе однобазового класса и обращаться к ним единообразно при сохранении специфического поведения каждого из объектов. Так, операция сравнения различных объектов возможна только тогда, когда базовый класс определяет метод сравнения.
Для того чтобы дальнейшее изложение было понятно, необходимо привести основные термины ООП:
АБСТРАКТНЫЙ ОБЪЕКТ (ABSTRACT OBJECT) - основным назначением абстрактного объекта является создание базового объекта, который затем может быть наследован другими объектами. Экземпляры абстрактного объекта никогда не создаются. Использование абстрактных объектов позволяет связать несколько объектов в одну иерархию объектов.
БИБЛИОТЕКА КЛАССОВ (Class Library) - набор готовых объектов общего назначения.
ВИРТУАЛЬНЫЙ МЕТОД (virtual method) - метод, адрес которого известен только в момент выполнения программы. Когда происходит вызов виртуального метода, его адрес берется из таблицы виртуальных методов. Это называется непрямым вызовом.
ДЕРЕВО КЛАССОВ (class tree) - синоним термина иерархия объектов.
ДЕСТРУКТОР (destructor) - специальная процедура для освобождения памяти, занятой объектом. Если по завершении работы с объектом (перед его удалением из памяти) необходимо выполнение каких - либо специальных действий, они должны быть выполнены внутри деструктора.
ИЕРАРХИЯ КЛАССОВ (class hierarchy) - позволяет создавать классы-потомки существующих классов таким образом, что классы-потомки наследуют все данные и методы классов-предков. Иерархия классов создается объявлением абстрактного объекта в вершине иерархии и присвоением этому абстрактному объекту общего указателя на код и данные всей иерархии.
ИНКАПСУЛЯЦИЯ (Incapsulation) - объединение в типе данных объект полей данных и методов (процедур и функций), работающих с этими данными.
КЛАСС (Class) - синоним термина тип данных объект.
КОНСТРУКТОР (Constructor) - специальная процедура, инициализирующая экземпляр объекта, содержащий виртуальные методы, путем установки связи между экземпляром объекта и таблицей виртуальных методов.
МЕТОД (Method) - процедура или функция, определенная внутри объекта для работы с данными объекта. Методу доступны данные объекта без явной передачи их в качестве параметров. Возможно наследование методов. Методы могут быть стратегическими и виртуальными. Для виртуальных объектов существуют два специальных метода - конструктор и деструктор.
МНОЖЕСТВЕННОЕ НАСЛЕДОВАНИЕ (Multiple inheritauce) - наличие у объекта нескольких родителей.
НАСЛЕДОВАНИЕ (Inheritauce) - процесс получения данных и методов от объекта-предка. Возможно многоуровневое наследование.
ОБЪЕКТ (Object) - тип данных ОБЬЕКТ. Совокупность данных и процедур - операций над этими данными (называемых методами). Дополнительно объекты могут наследовать методы и данные объектов- предков. Термин ОБЬЕКТ является синонимом термина класс.
ОБЪЕКТЫ - КОНТЕЙНЕРЫ (Container object)
- объекты, способные хранить в себе другие объекты. Например, стек, очередь, дерево, динамический массив, хэш- таблица и другие подобные структуры.
ОБЪЕКТ - ПОТОМОК (Descendant object) - объект, наследующий методы и данные от объекта-предка.
ОБЪЕКТ - ПРЕДОК (Ancestor object) - объект, методы и данные которого наследует объект - потомок.
ПАРАМЕТР SELF (Self parametr) - формальный параметр, предаваемый каждому объекту. Содержит указатель на конкретный экземпляр объекта.
ПЕРЕОПРЕДЕЛЕНИЕ ( Override) - процесс создания у объекта- потомка новых методов с теми же именами, что и у объекта -предка, но с новыми функциями, это делает возможным расширение объектов.
ПЕРЕДАЧА СООБЩЕНИЯ (Message passing) - вызов метода для конкретного экземпляра объекта. Отличие сообщения от метода в том, что одно и то же сообщение может вызывать разные методы. Например,
Cirde.Draw
Figures.Draw
ПОДКЛАСС (Subclass) - это класс-потомок. Например, если класс В наследовал из класса А, то класс В является подклассом класса А.
ПОЗДНЕЕ СВЯЗЫВАНИЕ (Late binding)
- ситуация, при которой адрес вызываемого метода неизвестен до момента выполнения программы. Адресация разрешается путем использования таблиц виртуальных методов с адресами методов. Так же возможно и раннее связывание.
ПОЛИМОРФИЗМ (Polimorphism) - возможность использования методов с одинаковыми именами для работы с различными типами данных.
РАННЕЕ СВЯЗЫВАНИЕ (Early binding) - ситуация, при которой адрес вызываемого метода известен в момент компиляции / компоновки. Так же возможно и позднее связывание.
РАСШИРЯЕМОСТЬ (Extendibility)
- благодаря свойству наследования, объекты могут быть расширены новыми функциями и / или полями данных. Новый метод изменяет или расширяет функции унаследованного метода и заменяет его в объекте-потомке. Возможно так же добавление ряда новых методов к уже существующим.
СВЯЗЫВАНИЕ (Binding) - процесс, в результате которого вызывающая программа/ подпрограмма получает адрес вызываемой подпрограммы. Возможно раннее и позднее связывание.
СТАТИСТИЧЕСКИЙ МЕТОД (Static method) - метод, вызываемый с использованием раннего связывания (адрес которого известен в момент компиляции/ компоновки).
СУПЕРКЛАСС (Superclass) - в иерархии объектов каждый класс имеет только одного непосредственного предка, называемого ‘’ предком’’ или “ суперклассом”.
ТАБЛИЦА ВИРТУАЛЬНЫХ МЕТОДОВ (Virtual method table) - таблица, хранимая в сегменте данных. Эта таблица создается для каждого объекта, имеющего виртуальные методы. В этой таблице хранятся адреса описанных в объекте виртуальных методов.
ЭКЗЕМПЛЯР (Instance) - строго говоря, этот термин не является специфическим для ООП, но используется часто. Экземпляр - это объявленная переменная типа объект.
5. ПОСТРОЕНИЕ ОБЪЕКТНОЙ МОДЕЛИ
Теперь у нас есть все необходимые понятия, чтобы описать процесс построения объектной модели. Этот процесс включает в себя следующие этапы:
· определение объектов и классов;
· подготовка словаря данных;
· определение зависимостей между объектами;
· определение атрибутов объектов и связей;
· организация и упрощение классов при использовании наследования;
· дальнейшее исследование и усовершенствование модели.
Определение классов
Анализ внешних требований к проектируемой прикладной системе позволяет определить объекты и классы объектов, связанные с прикладной проблемой, которую должна решать эта система. Все классы должны быть осмыслены в рассматриваемой прикладной области; классов, связанных с компьютерной реализацией, как например список, стэк и т.п. на этом этапе вводить не следует.
Начать нужно с выделения возможных классов из письменной постановки прикладной задачи (технического задания и другой документации, предоставленной заказчиком). Следует иметь в виду, что это очень сложный и ответственный этап разработки, так как от него во многом зависит дальнейшая судьба проекта.
При определении возможных классов нужно постараться выделить как можно больше классов, выписывая имя каждого класса, который приходит на ум. В частности, каждому существительному, встречающемуся в предварительной постановке задачи, может соответствовать класс. Поэтому при выделении возможных классов каждому такому существительному обычно сопоставляется возможный класс.
Далее список возможных классов должен быть проанализирован с целью исключения из него ненужных классов. Такими классами являются:
· избыточные классы: если два или несколько классов выражают одинаковую информацию, следует сохранить только один из них;
· нерелевантные (не имеющие прямого отношения к проблеме) классы: для каждого имени возможного класса оценивается, насколько он необходим в будущей системе (оценить это часто бывает весьма непросто); нерелевантные классы исключаются;
· нечетко определенные ( с точки зрения рассматриваемой проблемы) классы;
· атрибуты: некоторым существительным больше соответствуют не классы, а атрибуты; такие существительные, как правило, описывают свойства объектов (например, имя, возраст, вес, адрес и т.п.);
· операции: некоторым существительным больше соответствуют не классы, а имена операций (например, телефонный_вызов вряд ли означает какой-либо класс);
· роли: некоторые существительные определяют имена ролей в объектной модели (например, владелец, водитель, начальник, служащий; все эти имена связаны с ролями в различных зависимостях объектов класса человек);
· реализационные конструкции: именам, больше связанным с программированием и компьютерной аппаратурой, не следует на данном этапе сопоставлять классов, так как они не отражают особенностей проектируемой прикладной системы; примеры таких имен: подпрограмма, процесс, алгоритм, прерывание и т.п.
После исключения имен всех ненужных (лишних) возможных классов будет получен предварительный список классов, составляющих проектируемую систему.
Подготовка словаря данных
Отдельные слова имеют слишком много интерпретаций. Поэтому необходимо в самом начале проектирования подготовить словарь данных, содержащий четкие и недвусмысленные определения всех объектов (классов), атрибутов, операций, ролей и других сущностей, рассматриваемых в проекте. Без такого словаря обсуждение проекта с коллегами по разработке и заказчиками системы не имеет смысла, так как каждый может по-своему интерпретировать обсуждаемые термины.
Определение зависимостей
На следующем этапе построения объектной модели определяются зависимости между классами. Прежде всего, из классов исключаются атрибуты, являющиеся явными ссылками на другие классы; такие атрибуты заменяются зависимостями.
Смысл такой замены в том, что зависимости представляют собой абстракцию того же уровня, что и классы, и потому не оказывают непосредственного влияния на будущую реализацию (ссылка на класс лишь один из способов реализации зависимостей).
Аналогично тому, как имена возможных классов получались из существительных, встречающихся в предварительной постановке прикладной задачи, имена возможных зависимостей могут быть получены из глаголов или глагольных оборотов, встречающихся в указанном документе. Так обычно описываются: физическое положение (следует_за, является_частью, содержится_в), направленное действие (приводит_в_движение), общение (разговаривает_с), принадлежность (имеет, является_частью) и т.п.
Затем следует убрать ненужные или неправильные зависимости, используя следующие критерии:
· зависимости между исключенными классами должны быть исключены, либо переформулированы в терминах оставшихся классов;
· нерелевантные зависимости и зависимости, связанные с реализацией, должны быть исключены;
· действия: зависимость должна описывать структурные свойства прикладной области, а не малосущественные события;
· тренарные зависимости: большую часть зависимостей между тремя или большим числом классов можно разложить на несколько бинарных зависимостей; в некоторых (очень редких) случаях такое разложение осуществить не удается; например, тренарная зависимость "Профессор читает курс в аудитории 628" не может быть разложена на бинарные без потери информации;
·
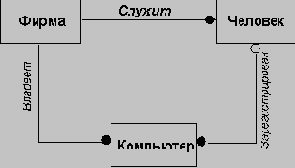 |
Рис. 5.1. Неизбыточные зависимости
Удалив избыточные зависимости, нужно уточнить семантику оставшихся зависимостей следующим образом:
· неверно названные зависимости: их следует переименовать, чтобы смысл их стал понятен;
· имена ролей: нужно добавить имена ролей там, где это необходимо; имя роли описывает роль, которую играет соответствующий класс в данной зависимости с точки зрения другого класса, участвующего в этой зависимости; если имя роли ясно из имени класса, его можно не указывать;
· кратность: необходимо добавить обозначения кратности зависимостей; при этом следует помнить, что кратность зависимостей может меняться в процессе дальнейшего анализа требований к системе;
· неучтенные зависимости должны быть выявлены и добавлены в модель.
Уточнение атрибутов
На следующем этапе уточняется система атрибутов: корректируются атрибуты классов, вводятся, в случае необходимости, новые атрибуты. Атрибуты выражают свойства объектов рассматриваемого класса, либо определяют их текущее состояние.
Атрибуты обычно соответствуют существительным; например цвет_автомобиля (свойство объекта), позиция_курсора (состояние объекта). Атрибуты, как правило, слабо влияют на структуру объектной модели.
Не следует стремиться определить как можно больше атрибутов: большое количество атрибутов усложняет модель, затрудняет понимание проблемы. Необходимо вводить только те атрибуты, которые имеют отношение к проектируемой прикладной системе, опуская случайные, малосущественные и производные атрибуты.
Наряду с атрибутами объектов необходимо ввести и атрибуты зависимостей между классами (связей между объектами).
При уточнении атрибутов руководствуются следующими критериями:
· Замена атрибутов на объекты. Если наличие некоторой сущности важнее, чем ее значение, то это объект, если важнее значение, то это атрибут: например, начальник - это объект (неважно, кто именно начальник, главное, чтобы кто-то им был), зарплата - это атрибут (ее значение весьма существенно); город - всегда объект, хотя в некоторых случаях может показаться, что это атрибут (например, город как часть адреса фирмы); в тех случаях, когда нужно, чтобы город был атрибутом, следует определить зависимость (скажем, находится) между классами фирма и город.
· Идентификаторы. Идентификаторы объектов связаны с их реализацией. На ранних стадиях проектирования их не следует рассматривать в качестве атрибутов.
· Атрибуты связей. Если некоторое свойство характеризует не объект сам по себе, а его связь с другим объектом (объектами), то это атрибут связи, а не атрибут объекта.
· Внутренние значения. Атрибуты, определяющие лишь внутреннее состояние объекта, незаметное вне объекта, следует исключить из рассмотрения.
· Несущественные детали. Атрибуты, не влияющие на выполнение большей части операций, рекомендуется опустить.
Далее необходимо постараться найти суперклассы для введенных классов. Это полезно, так как проясняет структуру модели и облегчает последующую реализацию.
Дальнейшее исследование и усовершенствование модели
Лишь в очень редких случаях построенная объектная модель сразу же оказывается корректной. Модель должна быть исследована и отлажена. Некоторые ошибки могут быть найдены при исследовании модели без компьютера, другие - при ее интерпретации совместно с динамической и функциональной моделями на компьютере (эти модели строятся после того, как объектная модель уже построена).
Здесь мы рассмотрим приемы бес компьютерного поиска и исправления ошибок в объектной модели. В их основе лежат внешние признаки, по которым можно находить ошибки в модели; эти признаки могут быть объединены в следующие группы.
Признаки пропущенного объекта (класса):
· несимметричности связей и обобщений (наследований); для исправления ошибки необходимо добавить пропущенные классы;
· несоответствие атрибутов и операций у класса; для исправления ошибки необходимо расщепить класс на несколько других классов, так чтобы атрибуты и операции новых классов соответствовали друг другу;
· обнаружена операция, не имеющая удовлетворительного целевого класса; для исправления ошибки необходимо добавить пропущенный целевой класс;
· обнаружено несколько зависимостей с одинаковыми именами и назначением; для исправления ошибки необходимо сделать обобщение и добавить пропущенный суперкласс.
Признаки ненужного (лишнего) класса:
· нехватка атрибутов, операций и зависимостей у некоторого класса; для исправления ошибки необходимо подумать, не следует ли исключить такой класс.
Признаки пропущенных зависимостей:
· отсутствуют пути доступа к операциям; для исправления ошибки необходимо добавить новые зависимости, обеспечивающие возможности обслуживания соответствующих запросов.
Признаки ненужных (лишних) зависимостей:
· избыточная информация в зависимостях; для исправления ошибки необходимо исключить зависимости, не добавляющие новой информации, или пометить их как производные зависимости;
· не хватает операций, пересекающих зависимость; для исправления ошибки необходимо подумать, не следует ли исключить такую зависимость.
Признаки неправильного размещения зависимостей:
· имена ролей слишком широки или слишком узки для их классов; для исправления ошибки необходимо переместить зависимость вверх или вниз по иерархии классов.
Признаки неправильного размещения атрибутов:
· нет необходимости доступа к объекту по значениям одного из его атрибутов; для исправления ошибки необходимо рассмотреть нужно ли ввести квалифицированную зависимость.
Динамическая модель системы или подсистемы
Объектная модель представляет статическую структуру проектируемой системы (подсистемы).
Однако знания статической структуры недостаточно, чтобы понять и оценить работу подсистемы. Необходимо иметь средства для описания изменений, которые происходят с объектами и их связями во время работы подсистемы. Одним из таких средств является динамическая модель подсистемы. Она строится после того, как объектная модель подсистемы построена и предварительно согласована и отлажена. Динамическая модель подсистемы состоит из диаграмм состояний ее объектов и подсистем.
События, состояния объектов и диаграммы состояний
Текущее состояние объекта характеризуется совокупностью текущих значений его атрибутов и связей. Во время работы системы составляющие ее объекты взаимодействуют друг с другом, в результате чего изменяются их состояния. Единицей влияния является событие: каждое событие приводит к смене состояния одного или нескольких объектов в системе, либо к возникновению новых событий. Работа системы характеризуется последовательностью происходящих в ней событий.
События
Событие происходит в некоторый момент времени (нередко оно используется для определения соответствующего момента времени). Примеры событий: старт ракеты, старт забега на 100 м, начало проводки (в банковской сети), выдача денег и т.п. Событие не имеет продолжительности (точнее, оно занимает пренебрежимо малое время).
Одно из событий может логически предшествовать другому, либо следовать за другим, либо они могут быть независимыми; примерами логически (причинно) связанных событий являются старт и финиш одного забега, начало проводки и выдача денег клиенту (в результате этой проводки), примерами независимых событий - старт ракеты и финиш забега и далее так и подобное тому. Если события не имеют причинной связи (т.е. они логически независимы), они называются независимыми (concurrent); такие события не влияют друг на друга. Независимые события не имеет смысла упорядочивать, так как они могут происходить в произвольном порядке. Модель распределенной системы обязательно должна содержать независимые события и активности.
События передают информацию с одного объекта на другой. Существуют классы событий, которые просто сигнализируют о том, что что-то произошло или происходит (примеры: загорание лампочки лифта, гудок в телефонной трубке). В программировании рассматриваются исключительные события (иногда их называют исключениями), которые сигнализируют о нарушениях работы аппаратуры, либо программного обеспечения.
Сценарии и трассы событий
Сценарием называется последовательность событий, которая может иметь место при конкретном выполнении системы. Сценарии могут иметь разные области влияния: они могут включать все события, происходящие в системе, либо только события, возникающие и влияющие только на определенные объекты системы.
Ниже приведен пример сценария пользования телефонной линией. Каждое событие в этом сценарии передает информацию с одного объекта на другой; например событие начинается, длинный гудок передает сигнал от телефонной линии к вызывающему (пользователю). При анализе динамики работы системы необходимо составить и рассмотреть несколько сценариев, отражающих типичные варианты ее работы.
вызывающий снимает трубку
начинается длинный гудок
вызывающий набирает цифру (9)
гудок прекращается
вызывающий набирает цифру (3)
вызывающий набирает цифру (9)
вызывающий набирает цифру ( )
вызывающий набирает цифру ( )
вызывающий набирает цифру ( )
вызывающий набирает цифру ( )
вызванный телефон начинает звонить
вызывающий слышит гудки
вызванный телефон отвечает
гудки прекращаются
телефоны соединены
вызванный по телефону вешает трубку
телефоны разъединены
вызывающий вешает трубку
Следующим этапом после разработки и анализа сценариев является определение объектов, генерирующих и принимающих каждое событие сценария.
Последовательности событий с привязкой к объектам проектируемой системы удобно представлять на диаграммах, называемых трассами событий. Пример трассы событий для разговора по телефону представлен на следующем рисунке. Вертикальные линии изображают на этой диаграмме объекты, а горизонтальные стрелки - события (стрелка начинается в объекте, генерирующем событие, и заканчивается в объекте, принимающем событие). Более поздние события помещены ниже более ранних, одновременные - на одном уровне.
 |
Состояния
Состояние определяется совокупностью текущих значений атрибутов и связей объекта. Например, банк может иметь состояния платежеспособный и неплатежеспособный (когда большая часть банков одновременно оказывается во втором состоянии, наступает банковский кризис).
Состояние определяет реакцию объекта на поступающее в него событие (в том, что реакция различна нетрудно убедиться с помощью банковской карточки: в зависимости от состояния банка обслуживание (реакция банка на предъявление карточки) будет разным). Реакция объекта на событие может включать некоторое действие и/или перевод объекта в новое состояние.
Объект сохраняет свое состояние в течение времени между двумя последовательными событиями, которые он принимает: события представляют моменты времени, состояния - отрезки времени; состояние имеет продолжительность, которая обычно равна отрезку времени между двумя последовательными событиями, принимаемыми объектом, но иногда может быть больше.
При определении состояний мы не рассматриваем тех атрибутов, которые не влияют на поведение объекта, и объединяем в одно состояние все комбинации значений атрибутов и связей, которые дают одинаковые реакции на события.
Диаграммы состояний
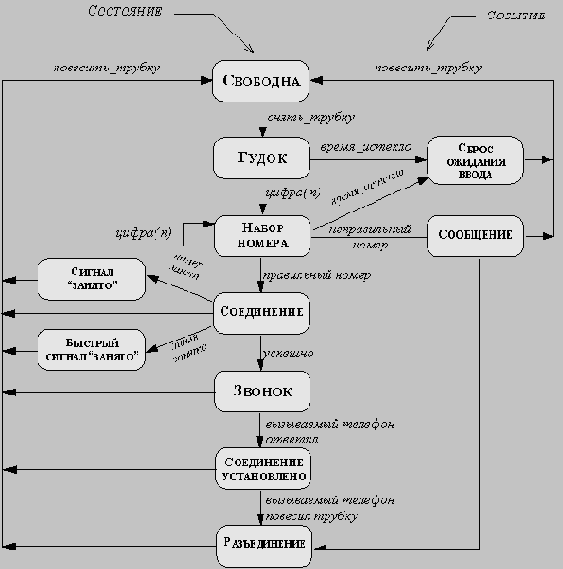
Диаграмма состояний связывает события и состояния. При приеме события следующее состояние системы зависит как от ее текущего состояния, так и от события; смена состояния называется переходом.
Диаграмма состояний - это граф, узлы которого представляют состояния, а направленные дуги, помеченные именами соответствующих событий, - переходы. Диаграмма состояний позволяет получить последовательность состояний по заданной последовательности событий.
Рис. 5.3. Диаграмма состояний телефонной линии
Активности и действия
Диаграмма состояний была бы не очень полезной, если бы она содержала только переходы (безусловные и условные), соответствующие генерируемым во время работы системы событиям. Являясь описанием поведения объекта, диаграмма состояний должна описывать, что делает объект в ответ на переход в некоторое состояние или на возникновение некоторого события. Для этого в диаграмму состояний включаются описания активностей и действий.
Активностью называется операция, связанная с каким-либо состоянием объекта (она выполняется, когда объект попадает в указанное состояние); выполнение активности требует определенного времени. Примеры активностей: выдача картинки на экран телевизора, телефонный звонок, считывание порции файла в буфер и т.п.; иногда активностью бывает просто приостановка выполнения программы (пауза), чтобы обеспечить необходимое время пребывания в соответствующем состоянии (это бывает особенно важно для параллельной асинхронной программы). Активность связана с состоянием, поэтому на диаграмме состояний она обозначается через "do: имя_активности" в узле, описывающем соответствующее состояние.
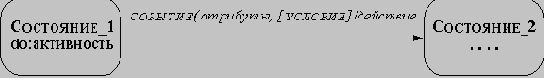
Рис. 5.4. Указание активностей и действий на диаграмме состояний
Действием называется мгновенная операция, связанная с событием: при возникновении события происходит не только переход объекта в новое состояние, но и выполняется действие, связанное с этим событием. Например, в телефонной сети событие повесил трубку сопровождается действием разъединить связь. Действие указывается на диаграмме состояний вслед за событием, которому оно соответствует, и его имя (или описание) отделяется от имени события косой чертой ("/").
Действия могут также представлять внутренние операции управления объекта, как, например, присваивание значений атрибутам или генерация других событий.
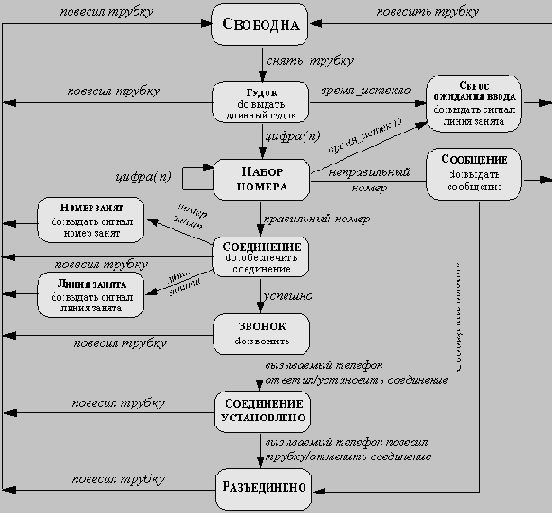
Рис. 5.5. Диаграмма состояний телефонной линии, на которой
указаны активности и действия
Одновременные события. Синхронизация
В системах, состоящих из нескольких параллельно работающих объектов, иногда бывает необходимо согласовать (синхронизировать) работу двух или более объектов. Для этого тоже используются события, так как синхронизация по существу состоит в необходимости задержать переход одного из синхронизируемых объектов в очередное состояние, пока другой объект не придет в некоторое фиксированное состояние, а переходы из состояния в состояние управляются событиями. Синхронизирующее событие может вырабатываться в любом из синхронизируемых объектов, либо в каком-либо третьем объекте.
Синхронизация используется и в случае, когда в каком-либо состоянии требуется параллельно выполнить несколько активностей.
Несмотря на то, что такие системы распространены в реальной жизни, их программирования стараются избегать, поскольку на данном этапе развития программных средств такая задача трудно решаема.
Функциональная модель подсистемы
Функциональная модель описывает вычисления в системе. Она показывает, каким образом выходные данные вычисляются по входным данным, не рассматривая порядок и способ реализации вычислений. Функциональная модель состоит из набора диаграмм потока данных, которые показывают потоки значений от внешних входов через операции и внутренние хранилища данных к внешним выходам. Функциональная модель описывает смысл операций объектной модели и действий динамической модели, а также ограничения на объектную модель. Неинтерактивные программы (например, компиляторы) имеют тривиальную динамическую модель: их цель состоит в вычислении значения некоторой функции. Основной моделью таких программ является функциональная модель (хотя если программа имеет нетривиальные структуры данных, для нее важна и объектная модель).
Диаграммы потоков данных
Функциональная модель представляет собой набор диаграмм потоков данных (далее - ДПД), которые описывают смысл операций и ограничений. ДПД отражает функциональные зависимости значений, вычисляемых в системе, включая входные значения, выходные значения и внутренние хранилища данных. ДПД - это граф, на котором показано движение значений данных от их источников через преобразующие их процессы к их потребителям в других объектах.
ДПД содержит процессы, которые преобразуют данные, потоки данных, которые переносят данные, активные объекты, которые производят и потребляют данные, и хранилища данных, которые пассивно хранят данные.
Процессы
Процесс преобразует значения данных. Процессы самого нижнего уровня представляют собой функции без побочных эффектов (примерами таких функций являются вычисление суммы двух чисел, вычисление комиссионного сбора за выполнение проводки с помощью банковской карточки и т.п.). Весь граф потока данных тоже представляет собой процесс (высокого уровня). Процесс может иметь побочные эффекты, если он содержит нефункциональные компоненты, такие как хранилища данных или внешние объекты.
На ДПД процесс изображается в виде эллипса, внутри которого помещается имя процесса; каждый процесс имеет фиксированное число входных и выходных данных, изображаемых стрелками (см. рисунок ).
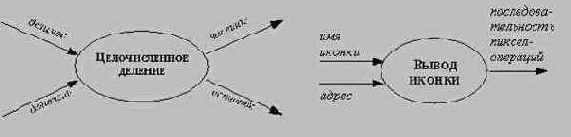
Рис. 5.6. Примеры процессов
Процессы реализуются в виде методов (или их частей) и соответствуют операциям конкретных классов.
Потоки данных
Поток данных соединяет выход объекта (или процесса) со входом другого объекта (или процесса). Он представляет промежуточные данные вычислений. Поток данных изображается в виде стрелки между производителем и потребителем данных, помеченной именами соответствующих данных; примеры стрелок, изображающих потоки данных, представлены на следующем рисунке. На первом примере изображено копирование данных при передаче одних и тех же значений двум объектам, на втором - расщепление структуры на ее поля при передаче разных полей структуры разным объектам.
 |
Активные объекты
Активным называется объект, который обеспечивает движение данных, поставляя или потребляя их. Активные объекты обычно бывают присоединены к входам и выходам ДПД. На ДПД активные объекты обозначаются прямоугольниками.
Хранилища данных
Хранилище данных - это пассивный объект в составе ДПД, в котором данные сохраняются для последующего доступа. Хранилище данных допускает доступ к хранимым в нем данным в порядке, отличном от того, в котором они были туда помещены. Агрегатные хранилища данных, как, например, списки и таблицы, обеспечивают доступ к данным в порядке их поступления, либо по ключам. Примеры хранилищ данных приведены на рисунке.
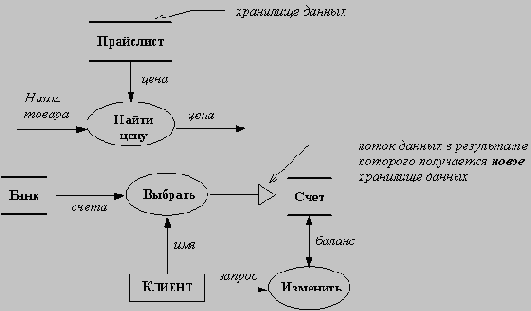 |
Потоки управления
ДПД показывает все пути вычисления значений, но не показывает, в каком порядке значения вычисляются. Решения о порядке вычислений связаны с управлением программой, которое отражается в динамической модели. Эти решения, вырабатываемые специальными функциями, или предикатами, определяют, будет ли выполнен тот или иной процесс, но при этом не передают процессу никаких данных, так что их включение в функциональную модель необязательно. Тем не менее, иногда бывает полезно включать указанные предикаты в функциональную модель, чтобы в ней были отражены условия выполнения соответствующего процесса. Функция, принимающая решение о запуске процесса, будучи включенной в ДПД, порождает в ДПД поток
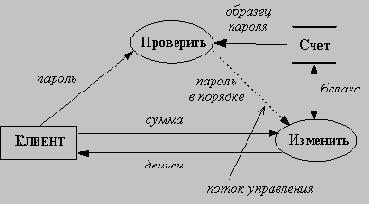 |
Рис. 5.9. Поток управления
На рисунке изображен пример потока управления: клиент, желающий снять часть своих денег со счета в банке, вводит пароль и требуемую сумму, однако фактическое снятие и выдача денег происходит только в том случае, когда введенный пароль совпадает с его образцом.
Несмотря на то, что потоки управления иногда оказываются весьма полезными, следует иметь в виду, что включение их в ДПД приводит к дублированию информации, входящей в динамическую модель.
Описание операций
Процессы ДПД, в конце концов, должны быть реализованы как операции объектов. Каждый процесс нижнего (базового) уровня, так же как и процессы верхних уровней, в состав которых входят процессы более нижних уровней, реализуются как операции. При этом реализация процессов верхних уровней может отличаться от их представления на ДПД, так как при реализации обычно производится их оптимизация: в результате оптимизации процессы нижних уровней, составляющие процесс более высокого уровня могут "слиться", после чего они станут невидимы.
Все операции должны быть специфицированы. Спецификация операции содержит ее сигнатуру (имя операции, количество, порядок и типы ее параметров, количество, порядок и типы возвращаемых ею значений) и описание ее эффекта (действия, преобразования). Для описания эффекта операции можно использовать:
· математические формулы;
· табличные функции: таблицы, сопоставляющие выходные значения входным;
· уравнения, связывающие входные и выходные значения;
· аксиоматическое определение операций с помощью пред- и пост-условий;
· таблицы принятия решений;
· псевдокод;
· естественный язык.
Пример описания операции - cпецификация операции изменить_счет (при описании эффекта операции использованы операции отменить_проводку, выдать_запрос, выдать_деньги, дебетовать_счет и кредитовать_счет):
изменить_счет (счет, сумма, вид_проводки) -> деньги, квитанция
если сумма снимается и больше баланса счета,
то "отменить_проводку"
если сумма снимается и меньше баланса счета,
то "дебетовать_счет" и "выдать_деньги"
если сумма вносится на счет
то "кредитовать_счет"
если запрос
то "выдать_запрос"
во всех случаях:
квитанция должна содержать дату, время, номер счета, вид проводки, сумму проводки (если она есть), новый баланс счета
Внешняя спецификация операции описывает только те изменения, которые видны вне операции. Операция может быть реализована таким образом, что при ее выполнении будут использоваться некоторые значения, определенные внутри операции (например, в целях оптимизации), некоторые из этих значений могут даже быть частью состояния объекта. Эти детали реализации операции скрыты от остальных объектов и не участвуют в определении внешнего эффекта операции. Изменения внутреннего состояния объекта, не видные вне его, не меняют значения объекта.
Все нетривиальные операции можно разделить на три категории: запросы, действия и активности. Запросом называется операция без побочных эффектов над видимым извне объекта его состоянием (чистая функция). Запрос, у которого нет параметров, кроме целевого объекта, является производным атрибутом. Например, для точки на координатной плоскости, радиус и полярный угол - производные атрибуты; из этого примера видно, что между основными и производными атрибутами нет принципиальной разницы, и выбор основных атрибутов во многом случаен.
Действием называется операция, имеющая побочные эффекты, которые могут влиять на целевой объект и на другие объекты системы, которые достижимы из целевого объекта. Действие не занимает времени (логически, оно совершается мгновенно).
Каждое действие может быть определено через те изменения, которые оно производит в состоянии объекта, меняя значения его атрибутов и связей; в каком порядке производятся эти изменения, несущественно: мы считаем, что все они происходят одновременно и мгновенно. Наиболее распространенным способом описания действия является задание алгоритма его выполнения на компьютере.
Активностью называется операция, выполняемая объектом, или над объектом, выполнение которой занимает определенное время. Активность имеет побочные эффекты. Активности могут быть только у активных объектов, так как пассивные объекты есть попросту склады данных.
Ограничения
Ограничение указывает на зависимость между соответственными значениями двух объектов, либо между различными значениями одного объекта. Ограничение может быть выражено в виде некоторой функции (количественное ограничение), либо отношения (качественное ограничение). Нас интересуют ограничения на атрибуты объектов, а также на состояния и события. Важным видом ограничений являются инварианты: утверждения о том, что значение некоторой функции от атрибутов, состояний и событий остается постоянным при функционировании объекта.
Анализ завершен
Цель анализа - обеспечить правильную постановку и адекватное понимание рассматриваемой прикладной задачи, помочь убедиться, что предварительно спроектированная прикладная система сможет удовлетворить заказчика. Хороший анализ охватывает все существенные особенности задачи, не внося каких-либо реализационных особенностей в предварительный проект системы. Тем самым обеспечивается свобода реализационных решений на этапе реализации.
Объектная модель показывает статическую структуру проблемной области, для которой разрабатывается система. Сначала определяются классы объектов, затем зависимости между объектами, включая агрегацию. Для упрощения структуры классов используется наследование. Объектная модель должна содержать краткие комментарии на естественном языке.
Динамическая модель показывает поведение системы, в особенности последовательность взаимодействий.
Сначала готовятся сценарии типичных сеансов взаимодействия с системой, затем определяются внешние события, отражающие взаимодействие системы с внешним миром; после этого строится диаграмма состояний для каждого активного объекта, на которой представлены образцы событий, получаемых системой и порождаемых ею, а также действий, выполняемых системой. Построенные диаграммы состояний сравниваются между собой, чтобы убедиться в их непротиворечивости. На этом построение динамической модели заканчивается.
Функциональная модель показывает функциональный вывод значений безотносительно к тому, когда они вычисляются. Сначала определяются входные и выходные значения системы как параметры внешних событий. Затем строятся диаграммы потоков данных, показывающие как вычисляется каждое выходное значение по входным и промежуточным значениям. Диаграммы потоков данных выявляют взаимодействие с внутренними объектами системы, которые служат хранилищами данных в периоды между сеансами работы системы. В заключение определяются ограничения и критерии оптимизации.
Вторая фаза жизненного цикла - конструирование системы
После того как прикладная задача исследована и результаты ее исследования зафиксированы в виде объектной, динамической и функциональной моделей, можно приступить к конструированию системы. На этапе конструирования системы принимаются решения о распределении подсистем по процессорам и другим аппаратным устройствам и устанавливаются основные принципы и концепции, которые формируют основу последующей детальной разработки программного обеспечения системы.
Внешняя организация системы называется архитектурой системы. Выбор архитектуры системы является еще одной задачей, решаемой на этапе ее конструирования.
Конструирование системы завершается конструированием ее объектов. На этом этапе разрабатываются полные определения классов и зависимостей, используемые на этапе реализации системы. Кроме того, определяются и конструируются внутренние объекты и оптимизируются структуры данных и алгоритмы.
Разработка архитектуры системы
Во время анализа требований к системе основное внимание уделялось выяснению того, что должно быть сделано, вне зависимости от того, как это сделать. На этапе разработки системы решается вопрос, как реализовать решения, принятые на этапе анализа.
Сначала разрабатывается общая структура (архитектура) системы. Архитектура системы определяет ее разбиение на модули, задает контекст, в рамках которого принимаются проектные решения на следующих этапах разработки. Приняв решения о структуре системы в целом, разработчик системы производит ее разбиение на относительно независимые в реализации части (модули), разделяя разработку между разработчиками выделенных модулей, что дает возможность расширить фронт работ, подключить к разработке системы новых исполнителей.
На этапе конструирования системы ее разработчик должен принять следующие решения:
· определить разбиение системы на модули;
· выявить асинхронный параллелизм в системе;
· определить состав вычислительного комплекса, на котором будет работать система;
· распределить компоненты системы по процессорам вычислительного комплекса и независимым задачам;
· организовать управление хранилищами данных;
· организовать управление глобальными ресурсами;
· выбрать принципы реализации управления программным обеспечением;
· организовать управление пограничными ситуациями.
Разбиение системы на модули
Первое, что необходимо сделать, начиная этап разработки системы, определить ее разбиение на некоторое количество компонентов - модулей. Модуль не является ни объектом, ни функцией; модуль - это набор (пакет) классов и отдельных объектов, подсистем, зависимостей, операций, событий и ограничений, которые взаимосвязаны и имеют достаточно хорошо определенный и по возможности небольшой интерфейс с другими модулями.
Часто модуль включает одну подсистему, являясь ее реализацией. Модуль (подсистема) обычно определяется через службы, которые он обеспечивает. Службой называется набор взаимосвязанных функций, которые совместно обеспечивают какую-либо функциональность, например, выполнение ввода-вывода, отрисовку картинок, выполнение арифметических действий. Подсистема определяет согласованный способ рассмотрения одной из сторон прикладной задачи, для решения которой разрабатывается рассматриваемая система. Например, система файлов - подсистема операционной системы; она обеспечивает набор взаимосвязанных абстрактных операций, которые в большой степени (но не полностью) независимы от абстрактных операций, обеспечиваемых другими подсистемами. Эта подсистема может быть реализована в виде отдельного модуля.
Как уже отмечалось, каждая подсистема имеет хорошо определенный (внешний) интерфейс с остальной частью системы (другими подсистемами). Этот интерфейс определяет форму всех взаимодействий с подсистемой и все потоки данных через ее границы, но не специфицирует внутреннюю структуру и внутреннее окружение подсистемы, а также особенности ее реализации. Поэтому каждая подсистема может разрабатываться независимо от остальных подсистем.
Подсистемы должны определяться таким образом, чтобы большая часть взаимодействий оставалась внутри подсистем, для уменьшения глобальных потоков данных и сокращения зависимостей между подсистемами. Подсистем должно быть не очень много (в пределах десятка). Некоторые подсистемы могут быть в свою очередь подразделены на подсистемы.
Две подсистемы могут взаимодействовать друг с другом либо как клиент и поставщик (клиент-сервер), либо как равноправные партнеры (сопрограммы). В первом случае клиент вызывает сервер, который выполняет некоторый запрос клиента и возвращает результат; клиент должен знать интерфейс сервера, но сервер может не знать интерфейсов клиента, так как все взаимодействия инициируются клиентом. В случае сопрограммного взаимодействия обе подсистемы вызывают друг друга.
Обращение подсистемы к другой подсистеме не обязательно связано с немедленным получением ответа. Сопрограммное взаимодействие является более сложным, так как обе подсистемы должны знать интерфейсы друг друга. Поэтому нужно стараться, чтобы большая часть подсистем взаимодействовала как клиент и сервер.
Подсистемы (и реализующие их модули) могут образовывать в системе уровни, либо разделы.
Уровни
Уровневая система может рассматриваться как упорядоченное множество виртуальных миров, каждый из которых построен на основе понятий, поддерживаемых его подсистемами; подсистемы одного уровня обеспечивают реализацию подсистем следующего уровня. Объекты каждого уровня могут быть независимыми, хотя нередко объекты разных уровней могут соответствовать друг другу. Каждая подсистема знает о подсистемах более низких уровней и ничего не знает о более высоких уровнях. Зависимость клиент-сервер существует между более верхним (клиент) и более нижними уровнями (серверы). При этом каждый уровень может иметь свой собственный набор классов и операций. Каждый уровень реализуется через операции объектов и подсистем более нижних уровней. Уровневые архитектуры бывают двух видов: открытые и замкнутые. В замкнутой архитектуре каждый уровень строится на базе непосредственно следующего за ним уровня. Это сокращает зависимости между уровнями и упрощает внесение изменений. В открытой архитектуре каждый уровень строится на базе всех следующих за ним уровней. Это уменьшает потребность в переопределении операций на каждом уровне и приводит к более эффективному и компактному коду. Однако открытая архитектура не удовлетворяет принципу скрытия информации, поскольку изменения в какой-либо подсистеме могут потребовать соответствующих изменений в подсистемах более высоких уровней.
Обычно лишь подсистемы самого верхнего и самого нижнего уровней могут быть выведены из постановки задачи: самый верхний уровень - это требуемая система, а самый нижний уровень - это доступные ресурсы: аппаратура, операционная система, имеющиеся библиотеки.
Промежуточные уровни вводятся разработчиком системы.
 |
Рис. 5.10
Пример системы с уровневой архитектурой
Разделы
Разделы подразделяют систему на несколько независимых или слабо связанных модулей (подсистем), каждая из которых обеспечивает один из видов услуг. Например, операционная система компьютера включает систему файлов, управление процессами, управление виртуальной памятью и управление устройствами.
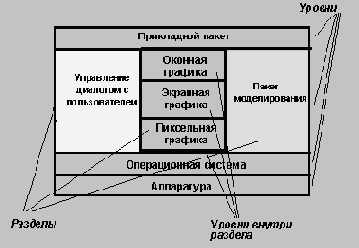 |
Рис. 5.11. Типичная структура системы
Топология системы
Когда все модули и подсистемы всех уровней названы, необходимо показать информационные потоки между модулями и подсистемами, построив ДПД. Это позволит понять топологию системы. Топология системы определяется совокупностью потоков информации в системе; например, у компилятора конвейерная топология; нужно стремиться, чтобы топология системы была как можно проще.
Выявление асинхронного параллелизма
В анализируемой модели, как и в реальном мире и в программном обеспечении все объекты независимы и должны работать асинхронно. Однако в реализации не все объекты должны работать независимо и асинхронно, так как несколько объектов может выполняться на одном процессоре, если известно, что они не могут быть одновременно активными. Одна из важнейших целей разработки системы выяснить, какие объекты должны быть активными одновременно (параллельно), а какие бывают активными только в разное время. Эти последние объекты могут быть связаны в одну нить управления (задачу).
Для определения асинхронности (параллельного существования) объектов используется динамическая модель.
Два объекта являются существенно асинхронными, если они могут получать события в одно и то же время, не взаимодействуя друг с другом. Если события не синхронизируются, такие объекты не могут быть связаны в одну нить управления.
От асинхронных объектов нужно отличать полностью независимые объекты, которые не только выполняются независимо, но и не обмениваются данными в процессе своей работы. Полностью независимые системы удобны тем, что их можно поместить на разные аппаратные устройства, исключив при этом коммуникационные затраты.
Асинхронные объекты могут выполняться и на одном устройстве (процессоре), если оно имеет систему прерываний и поддерживает режим разделения времени. Во многих случаях необходимость выполнять объекты на разных устройствах следует из постановки задачи.
Управление хранилищами данных
Внутренние и внешние хранилища данных являются четкими точками раздела между подсистемами с хорошо определенными интерфейсами. В качестве хранилищ данных могут использоваться базы данных, файлы и другие структуры данных, размещенные во внешней или основной памяти. Выбор вида хранилища данных зависит от ситуации.
В базах данных обычно размещают данные, удовлетворяющие одному из следующих условий:
· данные, для которых требуется доступ на высоком уровне детализации со стороны многих пользователей;
· данные, которые могут эффективно управляться командами СУБД;
· данные, которые должны переноситься на многие платформы;
· данные, для которых требуется доступ со стороны нескольких прикладных программ.
В файлах удобно размещать данные, удовлетворяющие одному из следующих условий:
· данные, которых много, но которые плохо поддаются структуризации;
· данные с низкой информационной плотностью (например, дампы);
· "сырые" данные, подготавливаемые для баз данных;
· "летучие" данные, которые хранятся короткое время, а потом удаляются.
Управление глобальными ресурсами
Необходимо определить глобальные ресурсы и разработать механизмы управления доступом к ним. Глобальными ресурсами могут быть: процессоры, устройства внешней памяти, экран рабочей станции, логические имена (идентификаторы объектов, имена файлов, имена классов), доступ к базам данных и т.п.
Реализация управления программным обеспечением
Во время анализа все взаимодействия представляются в виде событий. Управление аппаратурой соответствует этой модели, но необходимо выбрать метод управления программным обеспечением системы. Существует два класса методов управления программным обеспечением: методы внешнего управления и методы внутреннего управления.
Известны три метода внешнего управления:
1) последовательное управление процедурами,
2) последовательное управление событиями,
3) параллельное асинхронное управление.
При последовательном управлении процедурами в каждый момент времени действует одна из процедур; это наиболее легко реализуемый способ управления.
При последовательном управлении событиями управлением занимается монитор (диспетчер).
При параллельном асинхронном управлении этим заведует несколько управляющих объектов (мониторов).
Внутреннее управление связано с потоками управления в процессах. Оно существует только в реализации и потому не является только последовательным или параллельным. В отличие от внешних событий, внутренние передачи управления, как, например, вызовы процедур или обращения к параллельным задачам контролируются программой и могут быть структурированы в случае необходимости.
Пограничные ситуации
Необходимо предусмотреть поведение каждого объекта и всей системы в пограничных ситуациях: инициализации, терминации и обвале.
Инициализация. Перед тем, как начать работать, система (объект) должна быть приведена в фиксированное начальное состояние: должны быть проинициализированы все константы, начальные значения глобальных переменных и параметров, задачи и, возможно, сама иерархия классов. Во время инициализации, как правило, бывает доступна лишь часть возможностей системы.
Терминация. Терминация состоит в освобождении всех внешних ресурсов, занятых задачами системы.
Обвал. Обвал - это незапланированная терминация системы. Обвал может возникнуть в результате ошибок пользователя, нехватки ресурсов, или внешней аварии. Причиной обвала могут быть и ошибки в программном обеспечении системы.
Обзор архитектур прикладных систем
Существует несколько типов архитектур, обычно используемых в существующих системах. Каждая из них хорошо подходит к определенному типу систем. Проектируя систему одного из нижеперечисленных типов, имеет смысл использовать соответствующую архитектуру. Мы рассмотрим следующие типы систем:
· системы пакетной обработки - обработка данных производится один раз для каждого набора входных данных;
· системы непрерывной обработки - обработка данных производится непрерывно над сменяющимися входными данными;
· системы с интерактивным интерфейсом - системы, управляемые внешними воздействиями;
· системы динамического моделирования - системы, моделирующие поведение объектов внешнего мира;
· системы реального времени - системы, в которых преобладают строгие временные ограничения;
· системы управления транзакциями - системы, обеспечивающие сортировку и обновление данных; имеют коллективный доступ;
Типичной системой управления транзакциями является СУБД.
При разработке системы пакетной обработки необходимо выполнить следующие шаги:
· Разбиваем полное преобразование на фазы, каждая из которых выполняет некоторую часть преобразования; система описывается диаграммой потока данных, которая строится при разработке функциональной модели.
· Определяем классы промежуточных объектов между каждой парой последовательных фаз; каждая фаза знает об объектах, расположенных на объектной диаграмме до и после нее (эти объекты представляют соответственно входные и выходные данные фазы).
·
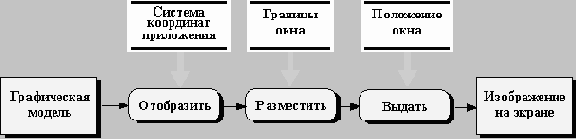 |
Рис. 5.12
Система непрерывной обработки: машинная графика
При разработке системы непрерывной обработки необходимо выполнить следующие шаги:
· Строим диаграмму потока данных; активные объекты в ее начале и в конце соответствуют структурам данных, значения которых непрерывно изменяются; хранилища данных, связанные с ее внутренними фазами, отражают параметры, которые влияют на зависимость между входными и выходными данными фазы.
· Определяем классы промежуточных объектов между каждой парой последовательных фаз; каждая фаза знает об объектах, расположенных на объектной диаграмме до и после нее (эти объекты представляют соответственно входные и выходные данные фазы).
· Представляем каждую фазу как последовательность изменений значений элементов выходной структуры данных в зависимости от значений элементов входной структуры данных и значений, получаемых из хранилища данных (значение выходной структуры данных формируется по частям).
При разработке системы с интерактивным интерфейсом необходимо выполнить следующие шаги:
· Выделяем объекты, формирующие интерфейс.
· Если есть возможность, используем готовые объекты для организации взаимодействия (например, для организации взаимодействия системы с пользователем через экран дисплея можно использовать библиотеку системы X-Window, обеспечивающую работу с меню, формами, кнопками и т.п.).
· Структуру программы определяем по ее динамической модели; для реализации интерактивного интерфейса используем параллельное управление (многозадачный режим) или механизм событий (прерывания), а не процедурное управление, когда время между выводом очередного сообщения пользователю и его ответом система проводит в режиме ожидания.
· Из множества событий выделяем физические (аппаратные, простые) события и стараемся при организации взаимодействия использовать в первую очередь их.
При разработке системы динамического моделирования необходимо выполнить следующие шаги:
· По объектной модели определяем активные объекты; эти объекты имеют атрибуты с периодически обновляемыми значениями.
· Определяем дискретные события; такие события соответствуют дискретным взаимодействиям объекта (например, включение питания) и реализуются как операции объекта.
· Определяем непрерывные зависимости (например, зависимости атрибутов от времени); значения таких атрибутов должны периодически обновляться в соответствии с зависимостью.
· Моделирование управляется объектами, отслеживающими временные циклы последовательностей событий.
Разработка системы реального времени аналогична разработке системы с интерактивным интерфейсом.
При разработке системы управления транзакциями необходимо выполнить следующие шаги:
· Отображаем объектную модель на базу данных.
· Определяем асинхронно работающие устройства и ресурсы с асинхронным доступом; в случае необходимости определяем новые классы.
· Определяем набор ресурсов (в том числе - структур данных), к которым необходим доступ во время транзакции (участники транзакции).
· Разрабатываем параллельное управление транзакциями; системе может понадобиться несколько раз повторить неудачную транзакцию прежде, чем выдать отказ.
Разработка объектов
Разработав архитектуру системы, переходим к разработке объектов (классов), составляющих систему. Часть объектов была выявлена на этапе анализа системы, эти объекты могут рассматриваться как основа системы. На рассматриваемом этапе разработки системы необходимо выбрать способ их реализации, стремясь минимизировать количество потребляемых ими ресурсов (времени их выполнения, используемой памяти и др.). При реализации объектов классы, атрибуты и зависимости должны быть реализованы в виде соответствующих структур данных, операции - в виде функций. При этом может возникнуть необходимость введения новых классов (объектов) для промежуточных данных.
Разработка объектов предполагает выполнение следующих шагов:
· Рассматривая совместно три модели, получаем операции над классами.
· Разрабатываем алгоритмы, реализующие полученные операции.
· Оптимизируем пути доступа к данным.
· Реализуем управление взаимодействиями с внешними объектами.
· Уточняем структуру классов, чтобы повысить степень наследования.
· Разрабатываем зависимости.
· Определяем представления объектов.
Совместное рассмотрение трех моделей
В результате анализа мы получаем три модели: объектную, динамическую и функциональную. При этом объектная модель составляет базу, вокруг которой осуществляется дальнейшая разработка. При построении объектной модели в ней не всегда указываются операции над объектами, так как с точки зрения объектной модели объекты это, прежде всего, структуры данных. Поэтому разработка системы начинается с сопоставления действиям и активностям динамической модели и процессам функциональной модели операций и внесения этих операций в объектную модель. С этого начинается процесс разработки программы, реализующей поведение, которое описывается моделями, построенными в результате анализа требований к системе.
Поведение объекта задается его диаграммой состояния; каждому переходу на этой диаграмме соответствует применение к объекту одной из его операций; можно каждому событию, полученному объектом, сопоставить операцию над этим объектом, а каждому событию, посланному объектом, сопоставить операцию над объектом, которому событие было послано. Активности, запускаемой переходом на диаграмме состояний, может соответствовать еще одна (вложенная) диаграмма состояний.
Результатом этого этапа проектирования является уточненная объектная модель, содержащая все классы проектируемой программной системы, в которых специфицированы все операции над их объектами.
Разработка алгоритмов, реализующих полученные операции
Каждой операции, определенной в уточненной объектной модели, должен быть сопоставлен алгоритм, реализующий эту операцию. При выборе алгоритма можно руководствоваться следующими соображениями:
· вычислительная сложность алгоритма: для алгоритмов, применяемых к достаточно большим массивам данных, важно, чтобы оценка их вычислительной сложности была разумной; например, вряд ли имеет смысл избегать косвенности в ссылках, особенно когда введение косвенности существенно упрощает понимание программы;
· понятность алгоритма и легкость его реализации: для достижения этого можно даже пойти на небольшое снижение эффективности; например, введение рекурсии всегда снижает скорость выполнения программы, но упрощает ее понимание;
· гибкость: большая часть программ рано или поздно должна быть модифицирована; как правило, высокоэффективный алгоритм труден для понимания и модификации; одним из выходов является разработка двух алгоритмов выполнения операции: простого, но не очень эффективного, и эффективного, но сложного; при модификации в этом случае изменяется более простой алгоритм, что обеспечивает работоспособность системы на период разработки более эффективного модифицированного алгоритма.
Выбор алгоритмов связан с выбором структур данных, обрабатываемых этими алгоритмами. Удачный выбор структур данных позволяет существенно оптимизировать алгоритм.
Еще одним способом упрощения и оптимизации алгоритмов является введение внутренних (вспомогательных) классов. Эти классы не имеют соответствий в реальном мире; они связаны с реализацией, но могут существенно упростить ее (примеры: класс стек, класс двусвязный список и т.п.).
Наконец, во многих случаях бывает полезным внести некоторые изменения в структуру объектной модели. Эти изменения сводятся к введению дополнительных классов и к перераспределению операций между классами.
При распределении операций по классам руководствуются следующими соображениями:
· если операция выполняется только над одним объектом, то она определяется в классе, экземпляром которого является этот объект;
· если аргументами операции являются объекты разных классов, то ее следует поместить в класс, к которому принадлежит результат операции;
· если аргументами операции являются объекты разных классов, причем изменяется значение только одного объекта, а значения других объектов только читаются, то ее следует поместить в класс, к которому принадлежит изменяемый объект;
· если классы вместе с их зависимостями образуют звезду с центром в одном из классов, то операцию, аргументами которой являются объекты этих классов, следует поместить в центральный класс.
Оптимизация разработки
Объектная модель, построенная на этапе анализа требований к программной системе, содержит информацию о логической структуре системы; на этапе разработки объектная модель уточняется и пополняется: в нее добавляются детали, связанные с необходимостью обеспечить более эффективный доступ к информационным структурам во время работы системы. Цель оптимизации разработки - заменить семантически корректную, но недостаточно эффективную модель, построенную на этапе анализа, более эффективной.
В процессе оптимизации разработки выполняются следующие преобразования:
· добавляются избыточные зависимости, чтобы минимизировать потери, связанные с доступом к данным, и максимизировать удобство работы с ними;
· изменяется порядок вычислений для достижения большей эффективности;
· сохраняются производные атрибуты, чтобы устранить необходимость перевычисления сложных выражений.
На этапе анализа требований к программной системе избыточные зависимости нежелательны, так как они не вносят в модель новой информации.
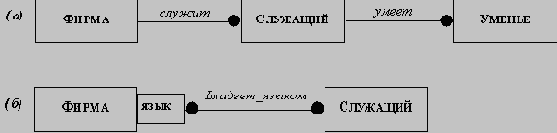 |
Однако на этапе разработки мы должны приспособить структуру объектной модели к требованиям эффективной реализации системы. Пример использования избыточной (производной) зависимости для повышения эффективности поиска представлен на рисунке : на рисунке (а) показаны зависимости из исходной объектной модели; добавление производной (и, следовательно, избыточной) зависимости (рисунок (б)) позволяет резко ускорить поиск сотрудников, говорящих по-китайски.
Ускорение поиска с помощью производной зависимости
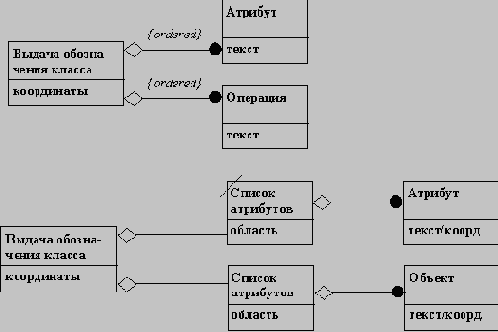 |
Рис. 5.14. Использование производных атрибутов для исключения
повторных вычислений
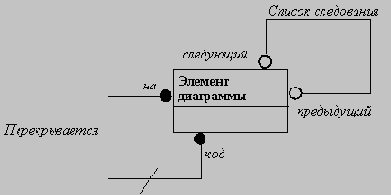 |
На предыдущем рисунке показано, как введение производной зависимости позволяет не перевычислять координаты перекрывающихся элементов окон в оконной системе для графического дисплея.
Производные атрибуты должны изменять свои значения, когда меняются их базовые значения. Для обеспечения этого пользуются одним из трех методов:
· явное перевычисление: каждый производный атрибут определяется с помощью одного или нескольких базовых объектов; когда значения базовых объектов меняются, требуется изменить значения всех производных атрибутов, связанных с ними;
· периодическое перевычисление всех производных атрибутов (в момент изменения базового значения производные атрибуты перевычисляются);
· использование активных значений: активным называется значение, с которым связано некоторое множество зависимых значений; все зависимые значения группируются вокруг определяющих их активных значений и перевычисляются синхронно с ними.
Реализация управления
Реализация управления связана с реализацией динамической модели объектов системы. Известны три подхода к реализации динамической модели:
· процедурное управление: состоянию соответствует определенный фрагмент программы;
· управление через события;
· использование параллельных независимых задач.
Процедурное управление является традиционным способом реализации динамической модели; в этом случае состояние объекта определяется текущим оператором программы, а каждому переходу соответствует оператор ввода: следующее состояние определяется по текущему состоянию и вводимому имени события.
Уточнение наследования классов
Уточняя определения классов и операций, стараемся увеличить степень наследуемости: чем больше классов находятся в отношении наследования, тем меньше функций, реализующих операции этих классов необходимо будет запрограммировать. Для увеличения степени наследуемости следует:
· Перестроить классы и операции.
· Выявить одинаковые (или взаимно однозначно соответствующие) операции и атрибуты классов и определить для этих классов абстрактный суперкласс.
· Использовать делегирование операций, когда наследование семантически некорректно.
Иногда одна и та же операция бывает определена в нескольких классах, что позволяет ввести общий суперкласс для этих классов, в котором и реализуется эта операция. Но чаще операции в разных классах бывают похожими, но не одинаковыми. В таких случаях нужно попытаться внести несущественные изменения в определения этих операций, чтобы они стали одинаковыми, т.е. имели одинаковый интерфейс и семантику. При этом можно использовать следующие приемы:
· Если операции имеют одинаковую семантику, но разное число формальных параметров, можно добавить отсутствующие параметры, но игнорировать их при выполнении операции; например, операция отрисовки изображения на монохромный монитор не требует параметра цвет, но его можно добавить и не принимать во внимание при выполнении операции.
· Некоторые операции имеют меньше параметров потому, что они являются частными случаями более общих операций; такие операции можно не реализовывать, сведя их к более общим операциям с соответствующими значениями параметров; например, добавление элемента в конец списка есть частный случай вставки элемента в список.
· Одинаковые по смыслу атрибуты или операции разных классов могут иметь разные имена; такие атрибуты (операции) можно переименовать и перенести в класс, являющийся общим предком рассматриваемых классов.
· Операция может быть определена не во всех классах некоторой группы классов; можно, тем не менее, вынести ее в их общий суперкласс, переопределив ее в подклассах как пустую там, где она не нужна.
Использование делегирования операций можно пояснить на следующем примере (рисунок ). Класс стек близок классу список, причем операциям стека push и pop соответствуют очевидные частные случаи операций списка add и remove. Если реализовать класс стек как подкласс класса список, то придется применять вместо операций push и pop более общие операции add и remove, следя за их параметрами, чтобы избежать записи или чтения из середины стека; это неудобно и чревато ошибками. Гораздо лучше объявить класс список телом класса стек (делегирование), обращаясь к операциям списка через операции стека. При этом, не меняя класса список, мы заменяем его интерфейс интерфейсом класса стек.
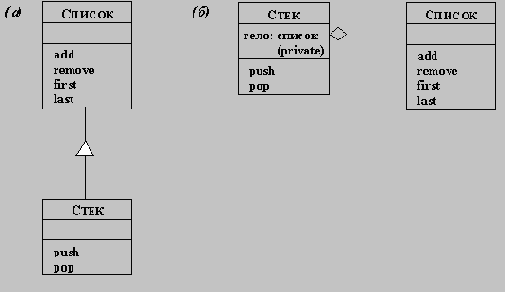 |
и делегирования (б)
Разработка зависимостей
Зависимости - это "клей" объектной модели: именно они позволяют рассматривать модель как нечто целое, а не просто как множество классов.
 |
Рис. 5.17. Реализация односторонней зависимости
 |
Рис. 5.18. Реализация двусторонней зависимости
Далее представлен способ реализации зависимости с помощью таблицы (как в реляционных базах данных).
 |
При реализации зависимостей с помощью указателей атрибуты зависимостей (связей) переносятся в один из классов, участвующих в зависимости.
Третья фаза жизненного цикла - реализация объектно-ориентированного проекта
Третья фаза жизненного цикла программной системы состоит в реализации разработанных программных единиц (классов, функций, библиотек), которые в совокупности составляют разрабатываемую программную систему. Реализация каждой программной единицы может осуществляться как на объектно-ориентированном, так и на не объектно-ориентированном языке программирования, с использованием ранее разработанных программ, библиотек и баз данных.
Каждый язык программирования имеет средства для выражения трех сторон спецификации разрабатываемой прикладной системы: структур данных, потоков управления и функциональных преобразований. Далее будут рассмотрены проблемы, решаемые на этапе реализации объектно-ориентированного проекта, разработанного с использованием методологии OMT.
Объектно-ориентированный стиль программирования
Правильно разработанные программы должны не только удовлетворять своим функциональным требованиям, но и обладать такими свойствами, как:
· повторная используемость;
· расширяемость;
· устойчивость к неправильным данным;
· системность.
Правильный объектно-ориентированный стиль программирования обеспечивает наличие этих свойств. Поясним это на примере свойства системности.
Программа обладает свойством системности, если она применима в качестве обобщенного оператора при "крупноблочном программировании". Крупноблочное программирование - это систематическое использование ранее разработанных крупных программных единиц (таких, как классы, подсистемы, или модули) при разработке новых программных систем.
Следующие рекомендации могут помочь разрабатывать классы, обладающие свойством системности.
· Методы должны быть хорошо продуманы.
· Методы должны быть понятны всем, кто их прочитает.
· Методы должны быть легко читаемы.
· Имена должны быть такими же, как и в модели.
· Методы должны быть хорошо документированы.
· Спецификации методов должны быть доступны.
Естественно, что к этим и им подобным "рекомендациям" следует относиться с известной долей юмора. Но выполнять их, тем не менее, полезно.
Объектно-ориентированные системы программирования
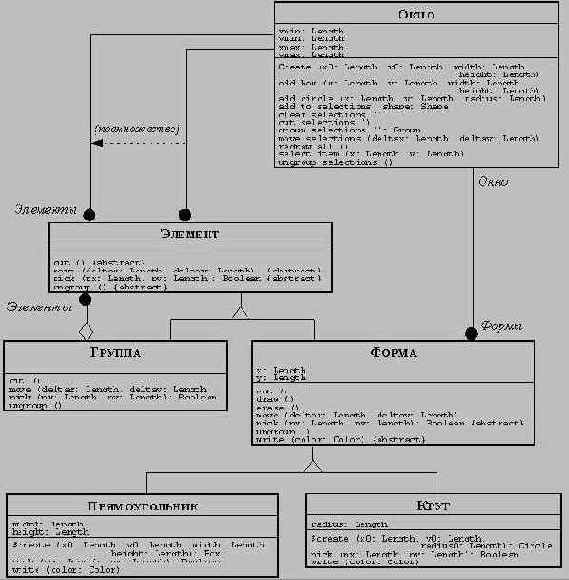
Рассмотрим проблемы реализации проекта, разработанного с использованием методологии OMT, в системах программирования объектно-ориентированных языков. В качестве примеров таких систем программирования будут рассмотрены системы программирования объектно-ориентированного языка C++.
Рис. 5.20
Все три модели методологии OMT, разработанные на этапе анализа требований к системе и уточненные на этапе ее проектирования, используются на этапе реализации программного обеспечения системы. Объектная модель определяет классы, атрибуты, иерархию наследования, зависимости. Динамическая модель определяет стратегию управления, которая будет принята в системе (процедурно-управляемая, событийно-управляемая, или многозадачная). Функциональная модель содержит функциональность объектов, которая должна быть воплощена в их методах.
Изложение будет вестись на примере реализации графического редактора, часть объектной модели которого представлена на рисунке. Редактор поддерживает манипулирование рекурсивными группами графических объектов, составленных из прямоугольников и овалов (в частности, кругов); при этом определена операция "сгруппировать", которая превращает группу объектов в единый объект (все это очень похоже на графическую подсистему редактора Microsoft Word).
Язык C++ является наиболее распространенным объектно-ориентированным языком программирования.
Далее приводится обзор свойств и конструкций этого языка. В настоящее время издано огромное количество учебных пособий, справочников и других руководств по языку C++. Одним из наиболее полных, изданных на русском языке, является книга Ирэ Пол. Объектно-ориентированное программирование с использованием C++. // DiaSoft Ltd., Киев -- 1995.
Реализация классов
Реализация прикладной программной системы, спроектированной с помощью объектно-ориентированной методологии (например, методологии OMT), на языке C++ начинается с определения классов, разработанных на этапе проектирования, на этом языке. При этом желательно сохранение имен и, по возможности, других обозначений, введенных на этапе проектирования. Рассмотрим в качестве примера, как реализовать на языке C++ класс Window, показанный на рисунке 5.1. Отметим, что реализация класса на языке C++ содержательно мало отличается от его представления в объектной модели OMT.
class Window
{
public:
// конструктор
Window (Length x0, Length y0, Length width, Length height);
// деструктор
~Window ();
// методы
void add_box (Length x, Length y, Length width, Length height);
void add_circle (Length x, Length y, Length radius);
void clear_selections ();
void cut_selections ();
Group* group_selections ();
void move_selections (Length deltax, Length deltay);
void redraw_all ();
void select_item (Length x, Length y);
void ungroup_selections ();
private:
Length xmin;
Length ymin;
Length xmax;
Length ymax;
void add_to_selections (Shape* shape);
};
В определении класса на языке C++ и атрибуты, и методы называются членами этого класса; их определения могут следовать в тексте определения класса в произвольном порядке.
Члены класса могут быть общедоступными (public), или приватными (private); вне класса определен доступ только к его общедоступным членам, а приватные члены доступны только методам своего класса. В рассматриваемом примере все атрибуты являются приватными, а все методы (кроме метода add_to_selections) - общедоступными, так что прочитать или изменить значение каждого атрибута можно только с помощью соответствующего метода; это рекомендуемая, хотя и не обязательная дисциплина программирования на языке C++ (определение всех атрибутов класса как приватных называется инкапсуляцией данных).
Тип Length должен быть определен пользователем (обычно такие определения делаются в одном из файлов-заголовков, вставляемых в программу по #include). Для определения типа используется оператор typedef. Например:
typedef float Length;
или
typedef int Length;
Порождение объектов
В каждом классе языка C++ могут быть определены специальные методы (один, или несколько), обращение к которым приводит к порождению нового объекта этого класса. Такие методы называются конструкторами. Конструкторы могут иметь параметры, что позволяет определить начальное состояние объекта при его порождении. Конструкторы имеют то же имя, что и имя класса, в котором они определены, так что если класс имеет несколько конструкторов, то они должны различаться числом и типом своих параметров. В качестве примера рассмотрим конструктор класса Window:
Window::Window (Length x0, Length y0, Length width, Length height)
{
xmin = x0;
ymin = y0;
xmax = x0 + width;
ymax = y0 + height;
}
При обращении к этому конструктору порождается новое окно с координатами нижнего левого угла (x0,y0), шириной width и высотой height. Наряду с рассмотренным в этом классе могут быть определены и другие конструкторы:
Window (Length x0, Length y0);//берутся стандартные размеры окна
Window (); //берутся стандартные размеры и положение окна
В языке C++ поддерживается три вида выделения памяти для размещения объектов: в фиксированной глобальной памяти (статическая память, static), в системном стеке (автоматическая память, automatic), в "куче" (динамическая память, dynamtic).
Чтобы разместить объект в статической памяти достаточно либо объявить его вне какой-либо функции, либо при его объявлении указать ключевое слово static. Статическая память выделяется компилятором во время компиляции программы и не меняется во время ее выполнения. Конструктор можно использовать для инициализации объектов, размещаемых в статической памяти (для выделения статической памяти под объект без его инициализации достаточно просто объявить его). Объявление
Window main_window = Window(0.0, 0.0, 8.5, 11.0)
определяет статический объект main_window (основное окно), проинициализированный значениями параметров конструктора.
Локальные объекты, объявляемые внутри функций, размещаются в автоматической памяти (системном стеке). Их тоже можно инициализировать с помощью конструктора. Наконец, обращение к конструктору в операторе new в процессе выполнения программы порождает объект, размещаемый в динамической памяти. Например:
Window *window = new Window (0.0, 0.0, 8.5, 11.0);
При этом выражение new Window (0.0, 0.0, 8.5, 11.0) имеет своим значением указатель на порожденный динамический объект.
Для терминации объектов можно использовать специальный метод, являющийся одним из членов класса и называемый деструктором. Как и конструктор, он имеет то же имя, что и имя класса, в котором он определен, но первым символом имени деструктора является тильда (~):
Window::~Window ();
{
… //убрать окно и перекрасить освободившуюся область
}
Наконец, для освобождения динамической памяти от объектов, которые уже не нужны, используется операция delete, например:
delete window;
Необходимость использования операции delete связана с тем, что в системе C++ не производится сборки мусора, и программист должен сам заботиться об освобождении динамической памяти от ненужных объектов, чтобы избежать ее переполнения (в более современной системе программирования Java обеспечивается автоматическая сборка мусора, что существенно упрощает программирование).
Вызов операций
В языке C++ операция (метод) определяется как один из членов класса. При вызове операции используются те же обозначения, что и при обращении к атрибутам: операция выбора члена "->" применяется к соответствующему указателю:
Shape* shape;
shape->move(dx,dy);
Параметрами операции могут быть значения одного из встроенных типов (int, float, char и т.п.), либо значения типов, определенных с помощью typedef, либо объекты некоторых классов, либо указатели переменных и констант перечисленных типов, либо указатели объектов.
Имя атрибута или операции, используемое в качестве идентификатора в реализации метода неявно ссылается на соответствующие члены объекта, к которому применяется операция. В следующем примере x и y являются атрибутами объекта класса Shape, к которому будет применена операция move:
void Shape::move (Length deltax, Length deltay)
{
x = x + deltax;
y = y + deltay;
}
Это эквивалентно применению неявного параметра this, значением которого всегда является указатель объекта, к которому применяется операция. Следующий фрагмент программы эквивалентен предыдущему:
void Shape::move (Length deltax, Length deltay)
{
this->x = this->x + deltax;
this->y = this->y + deltay;
}
Ссылка на любой другой объект в описании операции должна обязательно быть квалифицированной (содержать указатель соответствующего объекта):
window->xmin = x1;
Использование наследования
В языке C++ наследование устанавливается только при составлении программы и не может быть изменено в процессе ее выполнения. Поведение каждого объекта полностью определяется классом этого объекта и одинаково для всех объектов данного класса. Все характеристики наследования одинаковы для всех объектов каждого класса.
Список суперклассов (если он не пуст) указывается в начале определения каждого класса; подкласс называется также производным классом. В следующем примере приведено описание класса Item, а также описания подкласса Shape класса Item и подклассов Box и Circle класса Shape:
class Item
{
public:
virtual void cut ();
virtual void move (Length deltax, Length deltay) = 0;
virtual Boolean pick (Length px, Length py) = 0;
virtual void ungroup () = 0;
};
class Shape: public Item
{
protected:
Length x;
Length y;
public:
void cut ();
void draw () {write (COLOR_FOREGROUND);};
void erase (); {write (COLOR_BACKGROUND);};
void move (Length deltax, Length deltay);
Boolean pick (Length px, Length py) = 0;
void ungroup () { };
virtual void write (Color color) = 0;
};
class Box: public Shape
{
protected:
Length width;
Length height;
public:
Box (Length x0, Length y0, Length width0, Length height0);
Boolean pick (Length px, Length py);
void write (Color color);
};
class Circle: public Shape
{
protected:
Length radius;
public:
Circle (Length x0, Length y0, Length radius0);
Boolean pick (Length px, Length py);
void write (Color color);
};
Члены суперкласса (атрибуты и операции) наследуются его подклассами (члены, определенные в суперклассе, имеются у всех его подклассов). Члены суперкласса, определенные в нем как private, недоступны для операций его подклассов; для операций подклассов доступны члены суперкласса, определенные в нем protected и как public. Методы, определенные в суперклассе, могут быть переопределены в (некоторых) его подклассах, если они определены как виртуальные (virtual). Например, метод write класса Shape может быть переопределен в его подклассах Box и Circle, поэтому он определен как виртуальный; методы и в подклассах не переопределяются, поэтому их можно не объявлять как виртуальные. Если в определении виртуального метода указана его "инициализация" к 0 (virtual void write (Color color) = 0;), то он обязательно должен быть переопределен в каждом его подклассе (такой метод называется абстрактным). Класс, содержащий хотя бы один абстрактный метод, также называется абстрактным. Для абстрактных классов нельзя порождать объекты (объекты определены только для его подклассов). Если все методы класса определены как абстрактные, то говорят, что такой (абстрактный) класс определяет интерфейс, реализуемый в его подклассах.
В языке C++ поддерживается множественное наследование: каждый класс может иметь один или несколько суперклассов.
Реализация зависимостей
Зависимости в языке C++ реализуются с помощью указателей или с помощью специальных объектов. Например, зависимость "много-к-одному" между классами Item и Group реализована через указатели:
class Item{
public:
virtual void cut ();
virtual void move (Length deltax, Length deltay) = 0;
virtual Boolean pick (Length px, Length py) = 0;
virtual void ungroup () = 0;
private:
Group* group;
friend Group::add_item (Item*);
friend Group::remove_item (Item*);
public:
Group* get_group () {return group;};
};
class Group: public Item
{
public:
void cut ();
void move (Length deltax, Length deltay);
Boolean pick (Length px, Length py) = 0;
void ungroup () { };
private:
ItemSet* items;
public:
void add_item (Item*);
void remove_item (Item*);
ItemSet* get_items () {return items;}
};
Каждый раз, когда к зависимости добавляется ( или из нее удаляется) связь, оба указателя должны быть изменены:
void Group::add_item (Item* item)
{
item->group = this;
items->add (item);
}
void Group::remove_item (Item* item);
{
item->group = 0;
items->remove (item);
}
Методы Group::add_item и Group::remove_item могут изменять приватные (private) атрибуты класса Item, хотя они определены в его подклассе Group, так как они определены как дружественные (friends) для класса Item.
В рассмотренном примере опущены проверки:
1) не является ли включаемый в группу графический объект уже членом этой группы: в этом случае его незачем еще раз включать в группу;
2) не является ли включаемый в группу графический объект членом какой-либо другой группы: в этом случае его нельзя включать в группу и необходимо выдать на экран соответствующее сообщение.
Иногда связанные между собой (зависимые) объекты включают в так называемые коллективные классы. В качестве примера такого класса рассмотрим класс ItemSet (набор объектов):
class ItemSet
{
public:
ItemSet(); //создать пустой набор объектов
~ItemSet(); //уничтожить набор объектов
void add(Item*); //включить объект в набор
void remove(Item*); //исключить объект из набора
Boolean includes(Item*); //проверить наличие объекта в наборе
int size(Item*); //определить количество объектов в наборе
};
Коллективные классы часто используются в библиотеках классов. При работе с коллективными классами удобно использовать итераторы, т.е. объекты, с помощью которых можно "просмотреть" коллектив.
Зависимости между классами можно реализовать и с помощью специальных классов (каждый объект такого класса описывает связь между объектами соответствующих классов). В этом случае атрибуты класса соответствуют атрибутам описываемой им зависимости.
Дружественные функции
Дружественные функции – один из аспектов видимости в языке С++. Они представляют собой функции, которые описаны с модификатором friend в определении класса. Дружественным функциям разрешается читать и записывать поля данных объекта, описанные и как private, и как protected.
Дружественные функции являются мощным средством, но они также легко могут стать источником проблем. Везде где только возможно методы инкапсуляции должны иметь предпочтение перед дружественными функциями. Тем не менее есть случаи, когда нет других средств – например, функции требуется доступ ко внутренней структуре двух (или более) классов. В таких случаях дружественные функции бывают полезны.
Полиморфизм
В языках программирования полиморфный объект - это сущность (переменная, аргумент функции), хранящая во время выполнения программы значения разных типов. Полиморфные функции – это те функции, которые имеют полиморфные аргументы.
В объектно-ориентированных языках программирования полиморфизм – естественное следствие следующих особенностей:
- механизма пересылки сообщений;
- наследования;
- принципа подстановки.
Одно из важнейших достоинств объектно-ориентированного подхода состоит в возможности комбинирования этих средств. В результате появляется богатый набор технических приемов совместного и многократного использования кода.
Чистый полиморфизм имеет место, когда одна и та же функция применяется к аргументам различных типов. В случае чистого полиморфизма есть одна функция (тело кода) и несколько ее интерпретаций. Другая крайность наблюдается, когда имеется множество различных функций (то есть тел кода с одним и тем же именем). Такая ситуация называется перегрузкой или “полиморфизмом ad hoc” .
За исключение случав перегрузки полиморфизм в объектно-ориентированных языках программирования возможен только за счет существования полиморфных переменных. Полиморфная переменная может содержать значения, относящиеся к различным типам данных.
В языке С++ полиморфные переменные возникают при использовании указателей или ссылок.
(Для понимания дальнейшего материала нужны некоторые пояснения: будем использовать понятие статический тип для обозначения типа, присвоенного переменной при ее описании. Термин динамический тип характеризует тип фактического значения. Тот факт что статический и динамический тип не обязаны совпадать, является одним из главнейших достоинств объектно-ориентированного программирования.)
Когда настоящей переменной (то есть не указателю и не ссылке) присваивается значение типа подкласса, то динамический класс значения вынужденно приводится так, чтобы совпадать со статическим типом переменной. Однако при использовании указателей или ссылок значение сохраняет свой динамический тип.
Чтобы понять этот процесс, рассмотрим следующие два класса:
class One
{
public:
virtual int value( )
{
return 1;
}
};
class Two
{
public:
virtual int value ( )
{
return 2;
}
};
Класс One описывает виртуальный метод, который возвращает значение 1.
Этот метод переопределяется в классе Two на метод, возвращающий значение 2.
Определим следующие функции:
void directAssign (One x)
{
printf(“по значению переменная равна %d \ n”,
x .value ( ) );
}
void byPointer (One * x)
{
printf(“по указателю переменная равна %d \ n”,
x -> value ( ) );
}
void byReference (One & x)
{
printf(“по ссылке переменная равна %d \ n”,
x .value ( ) );
}
Эти функции используют в качестве аргумента значение класса One, которое передается соответственно по значению, через указатель и через ссылку. При выполнении этих функций с аргументом класса Two для первой параметр преобразуется к классу One, и в результате будет напечатано значение 1. Две другие функции допускают полиморфный аргумент. В обоих случаях переданное значение сохранит свой динамический тип данных, и напечатано будет значение 2.
Язык С++ позволяет нескольким функциям иметь одно имя внутри любого контекста до тех пор, пока списки аргументов функций различаются в достаточной степени, чтобы компилятор недвусмысленно определял, какую именно функцию намереваются вызвать. Такая ситуация, как правило, возникает при использовании нескольких конструкторов для одного и того же класса, каждый из которых имеет свой набор аргументов. Однако таким образом могут описываться любые функции, методы.
Правила для снятия двусмысленности с перегруженных функций являются довольно тонкими, в особенности если разрешено автоматическое приведение типов данных. Один из наиболее важных принципов, которые необходимо помнить: при поиске функции компилятор просматривает наиболее узкую область видимости, в которой определено имя функции, и затем в пределах этой области ищет подходящую функцию, основываясь на типе аргументов. То есть одна функция может скрыть другую с тем же именем, определенную в более широкой области видимости.
Шаблоны в языке C++
В любом языке программирования является обычным случай, когда имеется несколько функций, которые делают одно и то же, но с различными типами данных.
В языке C++ также возможно параметрическое программирование (программирование с использованием родовых компонентов). Родовые компоненты обладают свойством адаптивности к конкретной ситуации, в которой такой компонент используется, что позволяет разрабатывать достаточно универсальные и в то же время высокоэффективные компоненты программ (в частности, объекты).
В C++ определено два вида шаблонов: шаблоны-классы и шаблоны-функции.
Шаблоны-классы могут использоваться многими способами, но наиболее очевидным является их использование в качестве адаптивных объектов памяти.
Шаблоны-функции могут использоваться для определения параметризованных алгоритмов. Основное отличие шаблона-функции от шаблона-класса в том, что не нужно сообщать компилятору, к каким типам параметров применяется функция, он сам может определить это по типам ее формальных параметров.
Возможность параметрического программирования на языке C++ обеспечивается стандартной библиотекой шаблонов STL (Standard Template Library).
В библиотеке STL много разнообразного материала, так много, что перечислять его нет смысла, но за всей данной разработкой стоят несколько четких концепций, которые могут быть исключительно полезны для понимания всех составляющих STL. Первыми из них являются концепции контейнера(container) и итератора(iterator).
Контэйнер представляет собой объект, в котором другие объекты могут храниться, как массивы. Итератор представляет собой механизм, с помощью которого происходит обращение к объектам в контейнере. Например, в стандартном массиве вы располагаете индексом для обращения к элементам массива; этот индекс и есть итератор.
Эти контейнеры и итераторы реализованы в форме шаблонов. Реализация контейнера с шаблонами позволяет ему работать с любыми видами объектов.
Другой основной принцип STL касается скорее алгоритмов, которые не охватываются контейнером, а хранятся отдельно и являются весьма полезными для работы со всеми контейнерами.
Лучший способ описания STL – на примере. Листинг программы представляет собой пример использования контейнера list, содержащего связанный список объектов.
___________________________________________________________________
#include <iostream.h>
#include <list>
#include <string>
using namespace std;
// переименование некоторых типов для облегчения
//последующей работы при создании списка и его
//итератора.
typedef list <string> strList;
typedef list <string> :: iterator strIter;
int main( )
{
strList myList;
//
//Добавление строк
//
myList.insert(myList.end(),”first”);
myList.insert(myList.end(),”second”);
myList.insert(myList.end(),”third”);
myList.insert(myList.end(),”fourth”);
myList.insert(myList.end(),”fifth”);
myList.push_front(“Head”); //добавить в начало
myList.push_back(“Tail”); //добавить в конец
//Вывод списка
//
for (strIter iter=myList.begin( ); iter !=myList.end(); ++iter)
cout << *iter << endl;
cout << endl; //добавление пустой строки
//Убираем один из элементов
//
myList.erase(find(myList.begin( ),myList.end( ), “third”));
// Сейчас показываем в обратном порядке
//
strIter iter = myList.end ( );
--iter;
for (int ix = myList.size( ) ; ix > 0 ; --iter ; --ix )
cout << *iter << endl;
return 0;
}
__________________________________________________________________
Первое, что представляет интерес в этой программе – тот факт что STL не использует расширения .h для своих заголовочных файлов.
Типы strList и strIter создаются, чтобы сделать код более удобочитаемым. В противном случае пришлось бы постоянно набирать громоздкие названия при описании списка контейнера и итератора.
Следующий интересный фрагмент – вызов элемента-функции insert списка контейнера. Аргументы этой функции элемента локализованы в контейнере, в который вставляется новый элемент; в нем же располагается и сам этот элемент.
Для записи элементов в коней списка вызывается элемент- функция end. Она возвращает итератор, указывающий на коней списка.
Элементы-функции push_front и push_back содержат один аргумент - объект, заносимый в контейнер, и добавляют элементы соответственно в начало и в конец контейнера.
Элемент-функция erase, довольно очевидна, поскольку она содержит один параметр: итератор, указывающий на местоположение удаляемого элемента списка. В данном случае итератор получен путем вызова алгоритма find. Параметрами при этом являются указатели итератора на начало и конец списка, а также объект, поиск которого осуществляется.
Результат выдаваемый программой:
Head
first
second
third
fourth
fifth
Tail
Head
fifth
fourth
third
second
first
Tail
Object Windows Library.Базовая структура OWL
Библиотека Object Windows Library (OWL), включенная в пакет Borland C++ является библиотекой С++ и позволяет сократить время и усилия, требуемые для разработки программ под Windows.
OWL содержит группы классов, каждая из которых направлена на определенный аспект программирования под Windows. Структура OWL использует множественные наследования, что позволяет классам инкапсулировать комбинации необходимых им возможностей.
Управление событиями: класс TEventHandler
Программист мало работает с этим классом напрямую. Функции, которые он представляет, доступны во многих других программных группах, благодаря механизму наследования в С++. Этот класс управляет сообщениями, с которыми взаимодействуют программы. Сообщения имеют вид постоянных потоков.
Потоковые и устойчивые объекты: класс TStreamableBase.
Этот класс, фактически, является частью обычной библиотеки классов, а не классом OWL. Он позволяет рассматривать некий класс в качестве потока и сохранять его в памяти или на диске для дальнейшего использования во время, в том числе и последующих выполнений программы. Это является экзотичным для небольших программ, но имеет большое значение для более сложных приложений.
Управление модулями: классы TModule, TApplication.
TModule, Tapplication - относятся к группе управления модулями. TModule отвечает за загрузку и за выгрузку библиотек DLL, в то время, как TApplication ответственен за инициализацию программы, управление ею в период выполнения и управление задачами, которые необходимы при завершении выполнения программ.
Управление окнами: класс TWindow.
Этот класс является базовым оконным классом и наследует свойства классов TEventHandler и TStreamableBase. Существуют различные типы окон, построенные на этом классе TWindow.
TFrameWindow - простое окно с рамкой и меню.
TDecoratedFrame - расширяет возможности по использованию интерфейсных элементов: строки состояния и панели инструментов.
TMDIFrame, TMDIChild, TDecoratedMDIFrame - являются классами многодокументного интерфейса (MDI) и используются для представления множественных окон в рамках одного приложения.
Другие функциональные группы предусмотрены для графики, диалоговых окон, печати и управления меню и обработки ошибок.
Пример программы с использованием OWL.
______________________________________________________________
#include <owl\framewin.h>
#include <owl\applicat.h>
class MainApp : public TApplication
{
public :
MainApp ( ) : TApplication ( ) { }
void InitMainWindow ( ) ; // переопределяет функцию класса TApplication
};
void MainApp :: InitMainWindow ( )
{
SetMainWindow (new TFrameWindow (0,”First OWL Program”));
}
int OwlMain (int, char **)
{
return MainApp ( ).Run ( );
}
Программа отображает простейшее окно Windows с заголовком «First OWL Program». Для ее завершения необходимо нажать Alt-F4 или открыть системное меню и выбрать Close.
Эта программа содержит два элемента: класс для управления окном и класс для управления приложениями.
Класс MainApp является производным от TApplication, класса, который обеспечивает инициализацию приложения, непрерывное управление сообщениями и необходимые действия при завершении приложения.
TApplicaton содержит виртуальную функцию IntMainWindow. В MainApp осуществляется перегрузка этой функции. Внутри этой функции делается вызов и устанавливается главное окно приложения со своим заголовком.
OwlMain вызывает функцию Run, и обработка по умолчанию в рамках OWL делает все остальное. (Run- это функция класса TApplication).
Механизм действия этой программы скрыт в построении классов. MainApp вызывает конструктор для TApplication внутри своего собственного конструктора. Это инициирует обработку по умолчанию для всех функций поддержки, кроме функции InitMainWindow, которая была перегружена посредством объявления функции-члена под тем же именем.
Функция InitMainWindow вызывает функцию SetMainWindow с тем, чтобы выделить ресурсы для объекта типа TFrameWindow и связать приложение с этим оконным объектом. На этой же строке выделяются ресурсы для этого объекта TFrameWindow путем вызова для него оператора new, и происходит передача в него заголовка окна (при вызове конструктора).
Два включенных в программу заголовочных файла предназначены для классов TFrameWindow (framewin.h) и TApplication (applicat.h). Программа для Windows должна иметь файл с расширением .DЕF, чтобы сообщить компоновщику, что делать с сегментами памяти и стеком. Borland C++ предоставляет такой файл \BC5\LIB|DEFAULT.DEF , который и был использован этой программой. Его следует добавить к списку файлов вашего проекта. Как правило, для небольших проектов не требуется изменение установок файла .DEF и файл, предоставляемый BorlandC++ можно использовать по умолчанию.
СОДЕРЖАНИЕ
Класс является основным элементом языка СИ, обеспечивающим ООП. Он представляет собой расширение структур языка СИ. В классах помимо определение данных допускаются определения выполняемых над ними функций. Кроме того, в них имеются средства управления доступа к данным, позволяющие организовать взаимодействие различных классов друг с другом и классов с обычными функциями.
Функции, входящие в класс, часто называются методами.
Определение классов иллюстрирует следующий пример:
// iarray.h
class iarray
{ int maxitems // максимальное число элементов
int citems // число элементов в массиве
int *items // указатель на массив
public:
// конструктор
array(int nitems);
// деструктор
_array();
// занесение элементов в массив
int putitem(int item);
// получение элемента из массива
int getitem(int ind; int &item);
//получение фактического числа элементов в массиве
int count({return citems;});
};
В определении даны объявления внутренних переменных класса (переменные состояния), а также прототипы методов, обеспечивающих работу с данными.
Приведенный класс предназначен для создания целых массивов заданной длины и для размещения в них целых значений. Назначение переменных пояснено соответствующими комментариями.
Класс iarray содержит в себе пять методов. Прототипы четырех из них даны в файле iarray.h, а для пятого метода дана полная реализация.
Сами исходные тексты методов класса iarray
приведены ниже:
// iarray.cop
# include “iarray.h”
//конструктор
iarray::iarray(int nitems)
{ items=new int[nitems];
maxitems=nitems;
citems=0;
}
//деструктор
iarray::_iarray()
{delete items;
}
//занесение элемента в массив
int iarray::putitem(int item)
{ if (citems<maxitems){
items[citems]=item;
citems++;
return 0;
}
else return –1;
}
//получение элемента из массива
int iarray::getitem(int ind, int &item)
{ if (ind>=0 && ind<citems){
item-items[ind];
return 0;
}
else return –1
}
Среди методов особое место занимают такие два метода, как конструктор и деструктор. С помощью конструктора, в данном случае, создается массив целых значений заданной длины. В нем фиксируется длина массива и устанавливается счетчик занятых элементов, а также производится распределение памяти под массив.
Последняя операция выполняется введенным в С++ оператором new. Он проще, чем функция malloc, так как при ее применении не требуется задавать размер выполняемой памяти в байтах и преобразовывать полученный указатель к конкретному типу.
Второй специальный метод- деструктор. С его помощью уничтожается созданный конструктором объект. Для уничтожения динамически созданных объектов в С++ используется оператор delete, выполняющий роль функции tree в СИ.
Методы putitem и getitem обеспечивают контролируемое обращение к элементам массива. В первом методе отслеживается возможность размещения нового элемента в массиве. Во втором - правильность задания индекса получаемого из массива элемента.
Метод count позволяет получить число включений в массив элементов. Он реализован прямо в исходном тексте заголовочного файла iarray.h.
Отметим, что при определении методов за пределами текста класса используется операция” ::”, например: int iarray::putitem()
Эта операция говорит о том, что областью действия метода putitem является класс irarray.
Коснемся теперь использования определенного нами класса. Можно привести следующий пример:
#include “iarray.h”
#include<iostream.h>
#include<stdlib.h>
#include<time.h>
int main()
{
iarray m(10);
int i,j,k;
int n;
randomize()
for (i=1;i<=s;i++)
{
m.putitem(rand());
}
n=m.count()
for(i=0;i<=n;i++){
m.getitem(i,j);
count<<j<<”\n”;
}
}
В этом примере создается объект m, принадлежащий классу iarray. Далее в массив m вводятся пять целых чисел, полученных путем обращения к датчику случайных чисел. Эти числа вводятся в выходной поток count, которому соответствует дисплей.
В данном примере мы сталкиваемся с понятием объект. Объектом является переменная m, объявленная как принадлежащая классу iarray. Объект- это конкретный экземпляр массива целых чисел.
Действия с объектами осуществляются с помощью методов, обращение к которым задается составными именами, например : m.putitem() или m.getitem();
Отметим, что в объявлении iarray m(10); также производит вызов конструктора, в котором собственно и выполняются действия по созданию массива.
Есть другая возможность создания объекта с помощью оператора new. Например, в следующем фрагменте программы:
iarray *a;
iarray *b;
int n1=10
int n2=20;
a=new iarray(n1);
b=new iarray(n2);
…………
delete a;
delete b;
, где динамически создаются два массива a и b, размерностью 10 и 20 соответсвенно.
2.1. Связь класса с внешней средой
В ООП широко используются абстрактные типы данных и скрытие информации. Следовательно, проблема взаимодействия классов со средой, в которой они используются, приобретает первостепенное значение.
Решается эта проблема путем управления доступом к элементам классов с помощью использования в определениях классов ключевых слов private, public и protected.
Описатель private говорит о том, что следующие за ним составляющие элементы класса скрыты внутри него и недоступны непосредственно во внешней среде. Обращение к ним допускается только внутри класса с помощью его методов.
Описатель public говорит о том, что следующие за ним элементы класса доступны во внешней среде. Обычно public указывается перед методами класса.
Отметим, что элементы класса не могут иметь описателей типа памяти automatic, extern. Они могут иметь дополнительно только описание static. Элемент класса с описателем static будет общим для всех объектов данного класса.
Помимо public и private в классах можно использовать ключевое слово friend, с помощью которого объявляется “дружественные “ ему функции и целые классы. Если в классе объявлен прототип функции с описателем friend, не принадлежащий ему, то эта функция получает право доступа к внутренним элементам класса, например:
class type{
private:
int prm;
public:
friend void ftype(type x,int y);
void ftype(type x,int y);
{ x.prm=y;}
В данном примере в “дружественной “ классу функции ftype осуществляется доступ к внутренней переменной prm объекта x, принадлежащего к классу type.
2.2. Отношения между классами
Одной из важнейших черт ОПП является наличие механизма наследования свойств одного класса другими классами. Он позволяет строить новые классы на базе ранее созданных и этим самым способствует повторной используемости результатов процесса программирования.
Программа может включать в себя набор базовых классов, которые не связаны ни с какими другими. На основе базовых классов строятся производные классы, которые наследуют от базовых классов их структуры данных и методы. Таким образом, производные классы становятся расширением базовых, при этом они не включают в себя детали реализации базовых классов.
Рассмотрим пример, иллюстрирующий механизм взаимодействия между базовым и производными классами:
//bassear.h
class basearray
{protected:
int maxitems: //максимальное число элементов
int citems; //число размещенных элементов
public: //конструктор
basearray(int nitems){maxxitems=nitems; citems=0;};
};
//irray.h
class iarray : public basearray
{private:
int *items;
public:
iarray(int nitems); //конструктор
_iarrray(); //деструктор
int putitem(int item) //занесение элемента в массив
int getitem(int ind;int &item); // получение элемента из массива
int count({return citems;}); //получение числа элементов
};
Исходный текст методов класса iarray приведен ниже:
//iarray.cpp
#include “basearray.h”
#include “iarray.h”
iarray:iarray(int nitems):basearray(nitems) //конструктор
{items=new int[nitems];}
iarray::_iarray() //деструктор
{delete items;}
int iarray::putitem(int item) //занесение элемента в массив
{ if (citems<maxitems){
items[citems]=item;
citems++;
return 0;
}
else return –1;
}
int iarray:getitem(int ind,int &item) //получение элемента из массива
{ if(ind>=0 && ind<citems){
item=items[ind];
return 0;
}
else return –1;
}
int iarray::count(){return citems;}; //получение числа элементов
В новой версии реализации массива выделен базовый класс basearray, в котором определены общие для массивов составляющие, независимо от типов элементов. В производном классе определен конкретный тип массива. В нашем случае тип массива int, хотя можно определить тип массива как float, как struct и т.п.
Класс iarray наследует от класса basearray конструктор. При создании объекта типа iarray в конструкторе iarray вызывается конструктор basearray. С помощью механизма наследования осуществляется скрытие информации. Появившийся описатель protected говорит о том, что следующие за ним переменные будут доступны в производном и доступны в классах и функциях, не принадлежащим к этим классам.
2.3. Расширения языка С++
ФУНКЦИЯ inline
В функции #define проявляется много необычных эффектов связанных с многократным использованием аргументов. Все проблемы разрешила функция С++ inline, взятая из языка ADA. При обращение к функции с описателем inline не происходит реального вызова, а исполняется код функции, который транслятор вставляет непосредственно в место обращения.
Это значительно позволяет экономить время на вызове функции. Ограничение только на размер функции, она должна быть достаточно короткой, например:
Inline double sqr(double x){return x*x;}
Обычно функция помещается в header-файл- файл с расширением *.h, чтобы функция всегда была “под рукой” у транслятора. Другое ограничение, inline-функции не должны совершать циклы или ассемблерные вставки.
ФУНКЦИЯ OVERLOAD(ПЕРЕЗАГРУЖАЕМЫЕ)
Следующей функцией пришедшей из ADA является функция overload, позволяющая различить функции не только по имени, но и по типу аргумента, например:
double sqr(double x){return x*x;}
Обе спокойно уживаются в одной программе. При вызове будет использована одна из функций, какая решает тип аргумента.
ПАРАМЕТРЫ ФУНКЦИИ ПО УМОЛЧАНИЮ
Допустим, что вы имеете функцию для вывода матрицы в файл. Как правило, такие функции, для распечатки снабжаются большим количеством описаний, например:
print(matrix a,char *format=”%9.4”,char *title=null);
Задавать значение параметров лучше только один раз в разделе описаний.
Сделав это, обращение к функции может выглядеть так:
matrix c;
....
print(c);
или
print(c,”%12.7”);
ССЫЛКИ
Ссылка- это переменная, задаваемая указателем. Чтобы сделать переменную ссылкой, необходимо после описателя типа поставить оператор “&”. Ссылка во всем себя ведет так же, как и переменная того же типа, но при этом надо помнить, что на самом деле она совпадает с другой переменной, адрес которой указывается при объявлении ссылки, например:
int a;
int &b=&a;// переменная b совпадает с а.
Возникают ситуации, когда в функцию необходимо передавать не значения переменной, а ее адрес. Явная работа с адресами вызывает много неудобств при разработке функции и ее использовании. Теперь, при описании функции достаточно указать, что параметр передает по ссылке, и работать с ним не как с адресом, а как с переменной. Например, приведем функцию пересчета декартовых координат в полярные:
void polkar(double &x,double &y,double &FI,double &R){
R=sqrt(x*x*+y*y);
FI=atang(y,x);
}
А вот выглядит обращение к данной функции:
double X,Y,FI,R;
……..
poral(x,y,FI,R);
Таким образом, незаметно для нас параметры передаются в функцию через их адреса.
Таким образом, можно задать и тип возвращаемого значения, например:
Double &fuuc(int i);
ФУНКЦИИ- ЧЛЕНЫ СТРУКТУРЫ
Как правило, описав новую структуру, вы тут же создаете набор функций, работающих с этой структурой. Например, для структуры _3d, описывающей трехмерный вектор, можно записать функцию:
double mod(_3d &x);
которая будет вычислять модуль вектора. Здесь вы описываете функцию, вычисляющую модуль вектора, который передается ей через формальные параметры. Между тем модуль- характеристика присущая каждому вектору.
Поэтому будет логично, если вектор будет как бы сам возвращать свою длину, например:
_3d R;
double a;
…..
a=mod(R); //традиционный подход СИ
a=R.mod(); //это новый подход С++
На первый взгляд не видно большой разницы, однако, для больших функция это сказывается сильно. Для того чтобы функция стала членом структуры, достаточно поместить ее описание внутрь фигурных скобок, например:
Struct _3d{
double x,y,z;
double mod():
};
При описании реализации функции надо после типа возвращаемого значения указать имя структуры, членом которой является данная функция, отделив от него имя функции двойным двоеточием, например: double _3d::mod(){return sqrt(x*x+y*y+z*z);}
Покончив с формой, перейдем к содержанию. Наивно было бы думать, что создается новая копия функции для каждой новой переменной данного типа. Каждая функция представлена в единственном экземпляре и получает один срытый параметр- указатель на ту переменную, для которой она вызвана( называется рабочей переменной). К этому указателю можно обратиться по имени this. Если есть оператор а=R.mod(); то this при этом вызове соответствует адресу R, а функция mod() может быть реализована так:
double _3d::mod(){
return sqrt(this-.x*this-.x+
this-.y*this-.y+
this-.z*this-.z);}
Если переменная не описана ни внутри функции, ни как глобальная переменная, то считается, что она является членом структуры и принадлежит рабочей переменной *this. Поэтому можно опустить указатель this и к членам структуры обращаться просто по имени. Именно такой подход является ключевым в понимании ООП.
ПРИМЕР 1
Функция double _3d::proection(_3d r);
которая вычисляет длину проекции вектора R на рабочий вектор.
double _3d::proection(_3d r){
return(x*r.x+y*r.y+z*r.z)/sqrt(x*x+y*y+z*z);};
ПРИМЕР 2
Структура polar, определяет вектор в полярных координатах r,fi,l.
Для нее необходимо написать функцию _3dpoar::vect();
struct polar{
double if=cos(fi);
sf=sin(fi);
cl=cos(l),sl=sin(l);
_3d r;
r.x=r*sf*cl;
r.y=r*sf*sl;
r.z=r*if;
return r;
};
ПРИМЕР 3
Структура с_buffer, описывающая кольцевой буфер емкостью 1024 действительных числа.
Для нее надо описать функции:
void init(); //инициализация
void add(); //добавить элемент
double get(); //взять элемент
int free(); //величина свободного пространства
int used(); //величина занятого пространства
Буферизация, или организация очереди, - широко распространенное техническое решение. Один из способов реализации буфера - кольцевой буфер на одномерном ограниченном массиве. Идея такова. Имеется одномерный массив и две индексные переменные. Одна- индекс приемника <- указывает на элемент массива, куда записывается вновь поступающие значения. При записи индекс массива увеличивается на единицу. Вторая- индекс источника <- указывает га элемент массива из которого извлекается значение. При извлечении индекс источника тоже увеличивается на единицу. Если один из индексов выходит за границы, то он устанавливается на ее начало. В такой очереди могут стоять не только числа, но и объекты с более сложной структурой.
В соответствии с этим программа будет выглядеть так:
Struct C_Buffer{
double ptr[1024]; //массив буфера
int dest,scr; //DESTination- приемник,SouRCe- источник
void init(){src=dest==0;};
void add(double a);
double get();
int used();
int free();
};
void C_Buffer::add(double &a){
ptr[dest++]=a;
if)dest==1024)
dest=0;
};
int C_Buffer::used(){
int=dest-src;
if(n>=0)return n;
else return n+1024;
};
double C_Buffer::get(){
if(++src!=1024) return ptr[src-1];
src=0;
return ptr[1023];
};
int C_Buffer::free(){
int n=src-dest;
if(n>0) return n;
else return n+1024;
};
Функция int() нужна для инициализации указателей.
Обращение к ней обязательно пред использованием буфера.
Ближайшим родственником класса является структура. Если структуру поделить механизмом наследования, то она станет классом. Механизм наследования позволяет вновь создаваемым классами данных наследовать свойства уже существующих классов. Именно способность передавать и получать свои свойства по наследству отличает класс от структуры. Синтаксически класс описывается также, как и структура: сначала идет ключевое слово class, затем имя класса, затем, в фигурных скобках, члены класса- данные или функции. Все, что сказано о структурах, справедливо и для классов. Прежде чем пользоваться механизмом наследования, преобразуем уже имеющуюся у нас структуру _3d в класс:
class _3d{
public:
double x,y,z;
double mod();
};
double _3d::mod(){return(sqrt(x*x+y*y+z*z));};
Здесь описан класс с именем 3_d. Ключевое слово public означает, что нижеследующие члены класса общедоступны. Далее описаны три действительных числа, задающих координаты вектора. Обращение к членам класса осуществляется так же, как и к членам структуры, через точку.
Для классов применяется несколько другая терминология. Если раньше (в СИ) говорили о переменной данного типа, то теперь мы будем говорить об объекте данного класса, а функции- члены класса- будем называть методами данного класса.
2.4. Конструкторы и деструкторы
Создание объекта некоторого класса может быть достаточно сложной процедурой. Поэтому в С++ предусмотрены возможности явного описания процедур создания и уничтожения объектов данного класса. Процедуры создания объектов называются- конструкторами, а уничтожения- деструкторами. Конструкторы автоматически вызываются при описании объекта, а деструкторы- при выходе из блока, в котором этот объект был описан. Конструкторы в С++ имеют имена, совпадающие с именем класса, а различаются между собой аргументами. Деструктор может быть только один и имеет имя, совпадающее с именем класса, которому предшествует символ “~”.
И конструкторы и деструкторы не могут иметь описания типа.
Обратимся к ПРИМЕРУ 3, где мы описывали кольцевой буфер. Там нам нужна была функция init() для того, чтобы проанализировать индексы источника и приемника. Эта функция обязательно должна была вызываться для каждой создаваемой переменной этого типа. Если теперь мы преобразуем структуру C_Buffer в класс, то логично будет переделать функцию init в конструктор. Это пример, когда конструктор просто необходим при описании класса. Более редкий случай - когда необходимо применение деструктора. Деструктор нужен, например, для освобождения динамической памяти, занятой объектом.
Например, описание конструктора класса _3d:
Class _3d{
_3d(double &x,double &y,double &z){ x=X,Y=Y,z=Z;}
_3d(_3d&a){x=a.x;y=a.y;z=a.z;}
};
Если необходимые конструкторы или деструктор для класса не описаны, то транслятор создает их сам. Вызов конкретного конструктора для создаваемого объекта происходит в зависимости от аргументов, которые могут быть указаны в круглых скобках после имени создаваемого объекта, например: _3dA(0.0,1.0,0.0) , B;
Здесь для объекта А будет вызван описанный нами конструктор
_3d(double &x,double &y,double &z)
, а для объекта B - созданный транслятором _3d().
Существует специальный тип конструктора, который вызывается при выходе из функции, если та возвращает объект данного класса. Дело в том, что все объекты, описанные внутри функции, разрушаются (для них вызывается деструктор) при выходе из нее. Такой конструктор нужен для того, чтобы скопировать результат до того, как он будет разрушен. Это необходимо, например, для объектов, использующих динамическую память. В качестве аргумента в этом конструкторе выступает объект того же класса.
ПРИМЕР 4
Создать буфер значительного объема.
Необходимо изменить описание класса C_Buffer так, чтобы можно было задавать объем буфера при его объявлении. В состав класса вводится дополнительное поле - длина буфера.
Эта переменная подставляется везде вместо цифры 1024. Кроме того, вводится конструктор, который размещает массив ptr, и деструктор, который его освобождает.
class C_Buffer{
public
double *ptr;
int dest,scr;
int len;
C_Buffer(int len=1024);
Cbuffer(){if ptr!=null) free(ptr);
void add(double a);
double get();
int used();
int free();
};
C_Buffer::C_Buffer(int _len){
len=_len;
dest=src=0;
ptr=(double*)malloc(len* sizeof(double));
if(ptr==null)len=0;
}
void C_Buffer::get(double &a){
if(++src:=len)return ptr[src-1];
src=0;
return ptr[len-1];
};
int C_Buffer::used(){
int n=dest-src;
if(n>=0)return n;
else return n+len;
};
int C_Buffer::free(){
int n=src-dest;
if(n>0) return n;
else return n+len;
};
2.5. Правила доступности членов класса
При описании класса можно определять доступность членов класса для “чужих” функций. Вообще, в ООП считается хорошим тоном задавать все данные и служебные методы описываемого класса для доступа “извне”.
Так, в примере кольцевым буфером логично закрыть для доступа массив и оба указателя, чтобы с ними можно было работать только через методы add и get. Описывая класс, нужно оставлять доступ только к тем членам класса, которые необходимы для конкретной работы с объектами; всю сколько-нибудь сложную работу должны брать на себя методы данного класса.
В С++ существует три служебных слова, определяющих доступ членов класса. С первым из них вы уже знакомы, это PUBLIC. После этого слова двоеточие означает, что все нижеследующие члены класса будут считаться общедоступными, пока не встретиться другое описание доступности.
Другое слово PROTECTED- определяет, что члены класса доступны только дружественным функциям и классам, а также классам- наследникам данного класса.
Слово PRIVATE ограничивает круг “посвященных “ только дружественными функциями и классами.
Дружественные функции и классы - это функции и классы, упомянутые внутри описания класса с описателем FRIEND. Это слово ставиться самым первым в описании такой функции или класса.
ПРИМЕР 5
Ограничить доступ к членам класса C_Buffer так, как описано выше.
class C_Buffer{
protected:
double *ptr;
int dest,scr;
int len;
public:
C_Buffer(int len=1024);
_C_Buffer(){if ptr!=null) free(ptr);};
void add(double a);
double get();
int used();
int free();
int length(){return len)}
};
Метод length() позволяет проверить размещение массива.
2.6. Механизм наследования
Наследование заключается в том, что для вновь издаваемого класса мы можем указать классы, от которых он наследует их данные и методы. Такие классы мы будем называть предками, или порождающими классами, а новый класс- наследником, или порождаемым классом. Как правило, порождаемый класс имеет лишь одного предка. Иногда идеология задачи требует создания мощного дерева иерархии классов. Механизм наследования хорош отнюдь не тем, что он позволяет не описывать наследуемых членов класса. Дело в том, что транслятор выполняет скрытое преобразование типов “сверху-вниз”, то есть объект - наследник “сходит” за своего родителя. Иначе говоря, функции, работающие с объектами класса-предка, будут с тем же успехом работать и с объектами класса-наследника. При этом ”наследники” ведут себя аналогично “предкам”.
Для того чтобы задать отношения методу классами, надо при описании нового класса после имени класса поставить двоеточие и далее перечислять через запятую имена предков.
Предположим, что мы хотим ввести новый класс coord, описывающий систему координат в декартовом пространстве. Любая система координат задается положением центра и направлением осей. Так как центр системы координат задается вектором, то желательно, чтобы в некоторых случаях объекты класса coord вели себя аналогично объектам класса _3d.
Вот пример описания класса coord:
class coord:public _3d{
public:
_3d x,y,z;
};
Здесь описан класс-наследник класса _3d. Слово public перед именем класса-предка говорит о том, что общедоступные члены предка, наследуемые порождаемым классом, также общедоступны.
Членами класса coord являются действительные x,y,z, координаты центра (наследуемые) и три вектора X,Y,Z, задающие направление осей в пространстве. Объект этого класса может работать и как вектор. В этом случае он представляет собой положение центра системы координат.
ПРИМЕР 6
Используя класс BASE_List, приведенный ниже, опишите класс DoubleList, реализующий список, из действительных чисел.
Рассмотрим абстрактный класс BASE_List. Этот класс реализует двунаправленный линейный список. Список - это последовательность объектов некоторого класса, называемых его элементами. В любой момент времени доступно не более одного элемента списка. Доступ к другим элементам можно получить, последовательно перемещаясь от одного элемента к другому, к концу списка или к его началу. При этом возможны три особых состояния: список пуст , доступный элемент вначале списка и доступный элемент в конце списка.
Возможна вставка нового элемента перед доступным элементом или после него. Для этого служит метод: ins(int b, int before);
Где l- длина вставляемого элемента, before- указывает на то, что элемент должен вставляться перед доступным, если before отлично от нуля, и за ним - если равно. Вставляемый элемент становится текущим. Доступный элемент можно удалить: для этого служит метод del();. При этом становится доступным следующий к концу элемент (если его нет, то предыдущий).
Для перемещения одного элемента к другому используются операторы: ”++”- от начала к концу, ”- -“ - от конца к началу. Метод void*object(); возвращает адрес текущего элемента.
Решение заключается в том что, чтобы сделать более простым доступ к текущему элементу и упростить вставку.
Class DoubleList:virtual public Bas_List{
Public;
Int ins(int befr=1){
Return Base_List::ins(sizeof(TYPE),befr);
}
double&operator*(){
return*((double*)object());
}};
2.7. Виртуальные методы
Как же быть, если мы хотим, чтобы “наследник” вел себя отлично от “предка”, при этом сохраняя свойства совместимости с ним? На этот случай существуют виртуальные методы.
Виртуальный метод- это метод, который, будучи описан в потомках, замещает собой соответствующий метод везде- даже в методах, описанных для предка, если они вызываются для потомка.
Необходимость применении виртуальных методов возникает, если существует набор классов, обладающих схожими по смыслу методами, различающимися лишь реализацией (методы А), и если существуют идентичные по реализации методы, использующие методы А (методы Б).
В этом случае описывается базовый класс, для которого описывается виртуальные методы А. Как правило, методы А не конкретизируются (ставятся заглушки). После этого описываются методы Б, использующие методы А базового класса. Затем описываются классы, в которых методы А конкретизируются.
Возможен и другой взгляд на виртуальные методы. Предположим, что можно описать класс-концепцию, который послужит базовым ключом. Если для класса-концепции можно указать методы, которые будут иметь различную реализацию в производных классах, то их делают виртуальными. Виртуальные методы производных классов заменяют методы базового класса везде, где они упоминаются. Чтобы метод был описан как виртуальный, нужно перед его описанием поместить слово VIRUAL.
Проиллюстрируем все это на примере графических объектов. Опишем класс
GraphicsObject. Это класс имеет методы Build- построить, Display- показать, Hid- скрыть, Move- переместить. Идея этого класса заключается в том, чтобы можно было перемещать графическое изображение по экрану не измения его содержимого.
Метод Display запоминает изображение в некоторой области памяти и вызывает метод Build, который в этой области строит новое изображение. Метод Hid скрывает изображение, построенное методом Build, восстанавливая то изображение, которое запомнил метод Display. Наконец, метод Move вызывает метод Hid, чтобы скрыть старое изображение, и метод Display, чтобы построить его на новом месте.
Объявим метод Build виртуальным. Опишем теперь двух потомков класса GraphicsObject- Circle- имеет метод Build, который строит окружность.
Второй- Rectangle- имеет метод Build, который строит прямоугольник.
Программа, реализующая все это, выглядит так:
Circle A;
Rectangle B;
Если мы объявим так, то вызывая методы Display, Hid и Movе для объекта А, мы будем работать с кругом, а для объекта В - с прямоугольником.
class GraphicsObject{
protected:
int _x,_y;
void *image;
public:
void Display(int x,int y);
virtual void Build(int x, int y);
void Hid();
void Move(int x, int y);
};
classCircle:virtual public GraphicsObject{
virtual void Build(int x,int y); //строит кружок
};
class Rectangle:virtual public GraphicsObject{
virtual void Build(int x, int y); // строит прямоугольник
};
Если бы метод Build не был объявлен виртуальным, то при вызове А.Display вызывался бы метод: GraphicsObject::Build(int,int);
Но поскольку Build виртуальный, то вызывается Circle::Build(int,int);
Как же реализуется механизм виртуальных методов? Каждый объект, помимо полей данных, описанных для данного класса, содержит ссылку на таблицу адресов виртуальных методов своего класса. При вызове виртуального метода его адрес извлекается из соответствующей данному объекту таблицы - таким образом вызывается “то, что надо”. Объекты “таскают” свои виртуальные методы с собой.
3. История развития Турбо - Паскаля
Windows и Турбо - Паскаль появились одновременно, в 1983 году, однако их пути не пересекались до 1991. По сравнению с версией Windows 3.0 , ранние версии были медленными, со слабыми характеристиками и машинно-зависимыми. Однако Турбо Паскаль сразу же завоевал уважение и признание программистов не только своей стоимостью 50$ (а Windows - 500$), но и своими возможностями. Паскаль 1984 года - это дискета 360К и работа на машинах с самыми минимальными возможностями.
За эти годы шло совершенствование обоих программных продуктов, и, наконец, к 90 годам обе программы стали вполне зрелыми и работоспособными, имеющими массу приложений для пользователей и программистов.
Однако программирование Windows программ было все еще трудным делом, так как шла постоянная модернизация Windows (в 1993 году была выпущена последняя версия от версии W0.54).
Турбо Паскаль для Windows соединяет объектно-ориентированное расширение, появившееся в Турбо Паскале 5.5, с Windows API (Application Program Interface). С появлением Паскаля для Windows становится значительно быстрее и проще программировать приложения под Windows, так как отпала необходимость знать внутренности Windows , а знать только программирование. Турбо Паскаль для Windows содержит все, что вам необходимо для написания любой программы для Windows. К этому моменту Турбо Паскаль имеет уже мало общего с первой версией. Сейчас это значительный программный продукт с отличной средой разработки и многочисленными приложениями, упрощающие процесс разработки программ любой сложности.
Итак, первым вариантом объектно-ориентированного языка Паскаль стала версия 5.5 (запущенная в 1989). В этой версии появились ключевые слова Object, Constructor, Destructor и Virtual.
Автономный и удобный отладчик Turbo Debugger был расширен средствами работы с объектами - в него даже была включена программа просмотра иерархии объектов и способность вызывать объектные методы. Нельзя сказать, что жизнь Турбо Паскаля была безбедной, немного ранее фирма Microsoft выпустила Quick Pascal с собственным набором объектно-ориентированных расширений и с ценой ниже, чем предлагал Borland за Турбо Паскаль. Были введены: многооконный мышиный интерфейс, и многие удобные для программиста элементы, такие как измененный цвет комментариев и др. Однако, существенное отличие объектно-ориентированных расширений от общепринятых в С++ и в Турбо Паскале достаточно быстро устранили Quick Pascal с рынка. К настоящему времени, несмотря на существенные изменения, программный продукт фирмы Microsoft не пользуется спросом.
Первые шаги объектно-ориентированного программирования были сложны. Отсутствие литературы, доступных примеров не располагали к использованию объектно-ориентированного программирования.
Вскоре фирма Turbo Power Software выпустила библиотеку программ Object professional ,и объектно-ориентированное программирование стало неожиданно простым. Этот продукт содержит почти все мыслимые объекты, окна, меню, списки выбора, списки каталогов, массивы более 64К, резидентные модули и др. Эти объекты написаны так, что пользователи могут легко их изменять и расширять.
Шестая версия Турбо Паскаль появилась в 1990 году. Это уже полностью интегрированная среда, совмещенная с библиотекой Turbo Vission. Немного о Turbo Vission - событийно управляемом приложении. Вам не нужно начинать писать приложения, использующее Turbo Vission, с нуля, вам нужно просто выбрать из библиотеки соответствующий модуль и надстроить соответствующим образом. После этого программы могут считаться скорее событийно управляемыми, чем процедурными.
В истинно процедурных программах их выполнение происходит от одной строки до другой с вызовами подпрограмм и выполнением условных переходов. Вы можете писать такую программу, создавая необходимые подпрограммы и вызывая их в необходимой последовательности.
Событийно- управляемая программа, напротив, кажется почти хаотической. Телом такой программы является цикл наблюдения за входными действиями, такими как нажатие кнопок на клавиатуре или щелчок кнопкой мыши. Когда одно из таких действий происходит, программа переводит его во внутренний код события, после чего программа либо реагирует на событие и удаляет его из системы, либо передает его другому объекту. Это продолжается до тех пор, пока событие не обработано полностью или пока очередь сообщений, порожденных этим событием, не опустеет. Имеются такие события, которые передают всем объектам, и события, которые вызывают передачу сообщения от одного определенного объекта к другому. Написание событийно-управляемых программ включает создание объектов и наделение их способностью реагировать на соответствующие события. Это очень похоже на процесс создания программы для работы в среде Windows.
Турбо Паскаль для Windows - первый компилятор высокого уровня для Windows, имеющий интегрированную оболочку, базирующийся на концепциях Windows, является эволюционным расширением длинной линии компиляторов Турбо Паскаль.
Он вобрал в себя все достоинства, созданные в ходе развития Турбо Паскаля для Dos, за исключением тех, которые просто не имеют смысла в среде Windows.
Дополнительные языковые возможности являются результатом адаптации компилятора для Windows, а библиотека Object Windows (OWL) обеспечивает ясную, объектно-ориентированную среду, которая избавляет программиста от необходимости прямого обращения к функциям Windows API.
Программы, написанные на Турбо Паскале 6.0, могут быть преобразованы для Windows простой заменой Dos приложений на Windows приложения. Однако еще остались сложности разработки Windows программ. Версия под номером 7 немного расширила возможности Турбо Паскаля, но не добавила принципиально нового.
В объектно-ориентированном программировании данные неразрывно связаны с кодом программы, которая выполняет над ними операции. Вы не пишите процедуру для выполнения операций над данными; скорее вы пишите метод, позволяющий объекту изменять себя. Обычно весь важный программный код отделен от простых данных, которые полностью пассивны, поэтому понимание объектно-ориентированного образа мыслей требует серьезного пересмотра привычных методов мышления. Вы можете думать об объектно-ориентированном программировании как о более структурированной версии стандартного структурного программирования, используемого в Паскале, и как о более модульной версии модульного стиля языка Modula - 2.
Рассмотрим теперь объектно-ориентированные возможности Турбо Паскаля:
3.1. Совместное использование кода и данных
Объявление объекта Турбо Паскаля вначале выглядит так же, как и объявление записи; однако кроме полей данных типа Record оно содержит методы - процедуры и функции, которые оперируют с полями данных, как показано ниже:
TYPE
FrameRec = RECORD
TR: Trect;
Vis: Boolean;
Owner: hwnd;
END;
TFrame1=OBJECT ( Tobject )
TR: Trect;
Vis:Boolean;
Owner: hwnd;
constructor init ( iTR:TR; Own: hwnd);
destructor done; virtual;
procedure draw ( DC : hDC); virtual;
procedure hide;
procedure move ( x,y : integer);
END;
В этом примере секция данных окна включает тип Trect, который определяет размеры окна, логический тип, который определяет, видимо окно или нет, и дескриптор окна. Тип Record на этом завершается, но объектный тип также содержит ряд методов для работы с этими данными. Конструктор инициализирует объект и поле данных< а деструктор выполняет требуемые операции по освобождению памяти от объекта. Остальные методы отображают и изменяют объект - окно. Объединение данных и методов, воздействующих на эти данные, называется инкапсуляцией. В самой ее строгой форме инкапсуляция требует, чтобы вы никогда не обращались к полям объекта непосредственно - вы должны всегда использовать метод.
3.3. Повторное использование объектов
Одной инкапсуляции недостаточно, чтобы пробудить интерес к объектно-ориентированному программированию. Создание множества объявления данных и методов для каждого объекта может скоро надоесть. К счастью, вы не обязаны этого делать - вы можете объявлять один тип объекта потомком другого. Тип потомка наследует все поля и методы предка, так что вам не нужно описывать их снова и снова. Например,
TYPE
TFrame2 = OBJECT ( Tframe1)
Col : LongInt;
constructor Init ( itr : TRect ; Own : hwnd ; icol : LongInt);
Procedure Draw ( DC: hDC ) ; virtual;
END ;
Здесь объект Tframe2 наследует все поля данных Tframe1 и добавляет новое поле Col для хранения цвета. Чтобы инициализировать новое поле, требуется новый конструктор. Единственный метод, который должен быть изменен, - это Draw, который теперь должен выводить окно в цвете. Tframe2 перекрывает (override) существующий метод Draw и наследует оставшиеся методы. Объект - потомок наследует все поля данных предка и может содержать новые поля данных. По аналогии с полями наследует все методы предка и может так же содержать новые.
Но в отличие от полей данных, существующие методы могут быть перекрыты, чтобы изменить или расширить реализуемые им функции. Если существующий метод является виртуальным, объявление перекрывающего метода должно быть идентично объявления метода предка; если он является статическим, объявление может отличаться. Наследование упрощает расширение возможностей объекта, просто определяя потомка и добавляя особенности, которые вам необходимы.
3.4. Скрытые объекты
Обычные правила контроля соответствия типов Паскаля несколько упрощаются, когда это касается объектов. Указатель, объявленный как ссылка на один тип объекта, может указывать на любую переменную, чей тип наследуется от объявленного типа. Если процедура имеет параметр VAR, который имеет объектный тип, вы можете передавать в качестве параметра любой тип потомка этого типа. Следовательно, в этих ситуациях вы не можете и вам не надо знать фактический тип объекта. Объект полиморфен, т. е. он может иметь различные формы. Ваша программа может вызвать любой виртуальный метод, который представлен в объявленном типе объекта, и будет вызван именно тот метод, который соответствует фактическому типу. Это является наиболее удивительным аспектом объектно-ориентированного программирования. Предположим, что вы пишите и компилируете модуль, который вызывает виртуальный метод полиморфного объекта. Без повторной компиляции ваш модуль может вызвать этот метод для объекта, который не был еще даже задуман тогда, когда вы писали это!
Предположим, что мы расширяем объект Tframe1 иным способом, чтобы он отображал некоторый текст на экране, и делаем это следующим образом:
TYPE
Tframe3 = OBJECT ( TFrame1 )
Txt : Pchar;
CONSTRUCTOR Init ( itr : Trect ; Own : hwnd ; itxt :Pchar );
DESTRUCTOR Done ; virtual;
PROCEDURE Draw ( DC :hDC ); virtual;
END ;
Этот потомок объекта Tframe1 имеет поле Pchar, содержащее текст. Конструктор расширяется для инициализации этого текста, и новый метод Draw выводит окно с текстом.
Поскольку текст является переменной типа Pchar,- указатель на строку, завершающуюся нулем, - он должен освобождаться одновременно с освобождением объекта. Следовательно, TFrame3 перекрывает деструктор Done.
Поскольку Draw - виртуальный метод, отсюда следует, что для каждого потомка будет вызван правильный код. Объекты Tframe1 будут отображаться как черные окна, Tframe2 - как цветные окна и Tframe3 - как окна, содержащие текст.
3.5. Модульность
Хорошо отлаженные объекты являются чрезвычайно “ самосодержащими” и, следовательно, легко могут многократно использоваться и по мере необходимости расширяться. Объект взаимодействует с остальной частью программы только строго определенными способами. Строго говоря, основная программа не должна иметь никакого доступа к полям данных объекта, за исключением методов этого объекта. Кроме того, насколько это возможно, объекты должны ограничивать свои операции только их собственными данными и не должны быть связанными ни с какими глобальными переменными, а также не должны изменять их.
Модульность также помогает при управлении обработкой ошибок. Объект, разработанный с учетом требований модульности, подобен интегральной схеме. Сигналы поступают в схему и поступают от нее только через контакты (методы); нет никаких паразитных электрических соединений с другими элементами. Чтобы создавать прикладную программу, вы выбираете соответствующие компоненты и соединяете их. Именно так работает OWL (Object Windows Libraries): подключаете объект основного окна, некоторые порождаемые окна и несколько управляющих элементов - и ваша прикладная программа готова. Вы, вероятно, испытывали чувство, что каждая исправленная вами ошибка порождает еще две? Когда объекты связываются друг с другом ровно настолько, насколько это необходимо, упрощается процесс отладки. Если вы можете локализовать ошибку до определенного объекта, вы можете легко выделить этот объект, особенно используя программу, специально созданную для его проверки. Если вы обнаружили и исправили ошибку, то можете просто подключить восстановленный объект обратно в программу.
Поскольку объект является “ самосодержащим ”, то изменения, которые вы в него внесли, вряд ли могут вызвать возникновение ошибки в другом месте.
Из этого следует, что модульное программирование облегчает разработку больших проектов. Работа нескольких программистов над одним проектом всегда усложняет дело, а разделение работы на отдельные объекты упрощает его. Другие члены группы не должны знать о том, что происходит внутри ваших объектов, вы только даете им объявление заголовка объекта, чтобы они знали, какие методы доступны, и описание того, что делает каждый метод. Вы можете также как угодно сильно изменять внутренние структуры ваших объектов, не беспокоясь о своих коллегах. До тех пор, пока заголовки методов остаются неизменными, все модификации внутренних структур объекта не оказывают никакого воздействия на другие объекты.
Модульность также удобна для макетирования. Для определенного объекта может возникнуть необходимость создать метод, который реализует сложный вычислительный алгоритм, и его написание будет отнимать много времени. Для того чтобы создание этого метода не задерживало создание всего проекта, вы можете поставить “ внешнюю заглушку”, которая представляет собой объект с методом, возвращающим заранее известное значение. Тогда вы можете работать над сложным методом столько времени, сколько потребуется, не задерживая работу другим коллегам, если они есть, и, не отвлекая свое внимание на более легкие детали.
3.6. Надежность
Следствием тех же особенностей, которые придают объектно-ориентированным программам модульный характер, является их высокая надежность. Хорошо спроектированные объекты очень слабо связаны с другими объектами; они соединяются друг с другом только тогда, когда это абсолютно необходимо. Таким образом, сводится к минимуму вероятность возникновения побочных эффектов и изменений в глобальных переменных, устраняя, таким образом, причины возникновения общих для большинства приложений ошибок. Когда вам нужен измененный объект, вы не корректируете исходный текст, что могло бы привести к возникновению новых ошибок.
Вместо этого вы расширяете объект, создавая его потомка, который перекрывает или добавляет методы к уже имеющемуся объекту. В этом случае должны проверяться и отлаживаться только новые методы.
Объекты также повышают надежность программ, облегчая разбиение проекта на отдельные относительно небольшие части. Одному человеку практически невозможно исследовать и протестировать весь проект, но каждый объект перед его подключением к проекту может быть полностью проверен. Поскольку взаимодействие между объектами минимально, то объекты, которые работают правильно в автономном режиме, почти наверняка будут работать правильно и в собранном виде.
3.7. Возможность многократного использования
Как часто вам приходится создавать действительно с “нуля” новую программу? Большая часть программирования представляет собой повторное использование одних и тех же или подобных подпрограмм после значительного или незначительного переделывания. Теоретически мы все пишем исходные тексты, которые могут быть многократно использованы, экономя, таким образом, массу времени при разработке. На практике же до появления объектно-ориентированного программирования написание исходного текста, который мог бы быть многократно использован, является довольно сложной задачей. Хотя для многократного использования кода объекты абсолютно не нужны, ничто в обычном Паскале не вынуждает применять многократное использование, и вы не извлекаете из этого никаких непосредственных выгод. Если вы создаете ваши объекты настолько модульными, насколько это возможно, то будет также повышаться степень их многократного использования, и вы сразу же оцениваете все эти преимущества. Когда объект не зависит от глобальных переменных или когда, не входящего в него самого, вы можете легко включать его в другую программу.
Тот факт, что программы Windows имеют стандартный пользовательский интерфейс, помогает многократно использовать объекты. Если вы изобретаете блок диалога выбора файла со всеми необходимыми функциями, то можете использовать в любой программе, не заботясь о том, будет ли он соответствовать стиль этой программы.
На самом деле, если вы посмотрите в подкаталог OWL, то найдете такой объект там. Чтобы создавать объекты с возможностью их многократного использования, вы можете добавлять методы, которые не являются необходимыми непосредственно в создаваемой вами в данный момент программе. Например, для объекта, представляющего собой связанный список объектов, необходимо иметь возможность добавления новых объектов к списку. Этого может быть достаточно для вашего проекта, но для многократного использования связанного списка объектов необходимо включить в него и другие методы типа нахождения и удаления заданного объекта, добавления объекта в определенную позицию в списке или определения, имеется ли объект в списке. Вы могли бы, конечно, добавить эти методы позже - в потомке объекта связанного списка. Однако если вы знаете методы, которые, скорее всего, будут необходимы позже, создавайте их сейчас.
Пытаясь максимально использовать возможности многократного использования, вы можете решить создавать для самого общего объекта OWL виртуальные методы. Реакции на каждую более чем 500 функций API - ведь в конечном итоге для объекта потомка может возникнуть необходимость в перекрытии любого из этих методов. Однако это может занять большую часть вашего сегмента данных. Для каждого типа объектов, к которому имеется ссылка в программе, создается таблица виртуальных методов, которая содержит 4 - байтный адрес каждого виртуального метода независимо от того, является он унаследованным или перекрытым. Это требует 2К данных на каждый тип объекта, а в программе OWL могут использоваться десяток таких типов. По умолчанию 16К автоматического сегмента данных используется для стека и локальной кучи, поэтому фактически только 48К доступны для данных. Чтобы предотвращать заполнение сегмента данных множеством VMT, в TPW изменяется механизм динамических методов.
3.8. Объектные ключевые слова Турбо Паскаля
Полезно знать общие термины, используемые в объектно-ориентированном программировании, но так же полезно знать специфические термины, используемые в реализации Турбо Паскаля.
Даже если вы еще не решили, будете ли вы применять объектно-ориентированное программирование, вы должны знать эти термины хотя бы для того, чтобы не использовать их в качестве идентификаторов.
Зарезервированные слова
Зарезервированные слова в Турбо Паскале недоступны для их использования в качестве идентификаторов. Например, вы не можете назвать переменную -She, а процедуру - procedure. Зарезервированные слова, которые относятся к объектам, это Constructor, Destructor , Object.
Конечно же, наиболее важное из них -Object. Оно появляется в объявлениях типа и очень похоже на зарезервированное слово Record. Подобно записи, объект имеет нуль или больше полей данных. Но в отличие от записи, он также имеет методы (процедуры и функции, которые оперируют с полями данных). Эти методы появляется в объявлении объекта как заголовок процедуры или функции - тело подпрограммы находится дальше. Часто объявление объектного типа помещается в секции интерфейса модуля, а реальные методы помещаются в секции реализации. Вы можете включить имя существующего объектного типа в круглые скобки после ключевого слова Object , указывая, что определяемый объект - потомок существующего объекта.
Любой объектный тип, определение которого включает виртуальные методы, должен иметь, по крайней мере, один конструктор. Эта подпрограмма служит для инициализации VMT (virtual method table) и, если необходимо, DMT (dynamic method table). Вы должны вызывать конструктор прежде, чем что-то делаете с таким объектом. Часто конструктор будет также выполнять некоторую инициализацию полей данных и операции выделения необходимых ресурсов системы Конструкторы могут инициализировать объект, загружая поля данных из потока. Поэтому конструкторы обычно называют либо Init, либо Load.
В общем случае, вам не следует вызывать конструктор из другого метода; однако, если вы так делаете, то должны быть абсолютно уверены, что задали имя конструктора полностью, т. е. поставили перед именем конструктора имя объектного типа с точкой в конце, как показано ниже:
ParentObject . Init
Этот шаг чрезвычайно важен - неправильно определенный вызов конструктора в методе, унаследованном экземпляром объекта - потомка, будет задавать вместо указателя VMT -объекта указатель родителя.
Метод - конструктор инициализирует объект и выделяет ресурсы, в которых он нуждается, деструктор служит для освобождения этих ресурсов. Деструктор должен освободить всю память в куче, используемую объектом, закрывать файлы и выполнять подготовку объекта к уничтожению. Деструкторы обычно называются Done. В иерархии объектов OWL корневой объект Tobject имеет виртуальный деструктор, который называется Done, а остальные OWL - объекты определяют или наследуют деструктор Done. Поскольку деструктор тесно связан с процессом освобождения ресурсов, Турбо Паскаль позволяет вам включать вызов деструктора в качестве необязательного второго параметра для встроенной подпрограммы Dispose. Всякий раз, когда вы объявляете локальную переменную объектного типа, вы должны вызывать деструктор перед завершением процедуры, в которой переменная объявлена.
Конструктор необходим для каждого объекта, который определяет или наследует виртуальные методы; деструктор требуется, только если объект выделяет ресурсы, которые должны возвращаться прежде, чем объект освобождается. Однако включение деструктора в вызове Dispose позволяет компилятору освобождать правильное количество байтов даже тогда, когда динамический объект используется полиморфно. Желательно включать виртуальный метод - деструктор в корень или близко к корню вашей иерархии объектов, даже если он состоит из пустой цепи Begin ... End.
Процедура обработки ошибок
Часто при вызове конструктора происходит выделение различных ресурсов системы, таких, как память. Если конструктор не может получить требуемые ресурсы, он должен иметь возможность сообщить вызвавшей его программе, что не смог инициализировать объект. Процедура Fail выполняет эти действия. Любой конструктор может обрабатываться, как обычная логическая функция, и он будет обычно выдавать значения True.
Только, если для выхода использовалась процедура Fail, конструктор будет выдавать значение False. Если конструктор делает вызов конструктора предка, при ошибке в объекте предка возникает и ошибка вызова конструктора. Если конструктор частично инициализировал объект перед ошибочным вызовом конструктора предка, он должен отменить частичную инициализацию. Рекомендуется использовать программу Fail только в исключительных случаях.
Параметры Self
Кроме явных параметров, указанных в определении метода, каждый метод также имеет неявный параметр Self. Этот параметр соответствует непосредственно экземпляру объекта, из которого метод вызывался, и все поля данных этого экземпляра доступны через параметр Self. В Турбо Паскале параметр Self подразумевается. Однако иногда необходимо ссылаться к полям объекта в неоднозначном контексте. Приведенный в примере конструктор должен ссылаться к полям параметра Self и к идентичным полям параметра Other. Явное использование параметра Self упрощает эту процедуру:
Constructor SomeType. CE From ( var other: SomeType)
begin
Self.foo:= other.foo;
Self.bar:= other.bar;
end;
3.9. Стандартные директивы VIRTUAL и PRIVATE
В отличие от зарезервированных слов, стандартные директивы могут переопределяться пользователем. Вы можете вполне корректно объявить переменную с именем virtual или процедуру с именем private, но, делая это, вы усложняете себе работу. Избегайте использования этих терминов в качестве имен идентификаторов также, как избегайте пользования других директив типа Absolute,Interrupt, far.
Если директива virtual появляется после объявления метода, данный метод имеет определенные специальные свойства и ограничения. Виртуальный метод может перекрывать статический метод предка, но обратное неверно. Если вы делаете метод виртуальным, то каждый потомок, который перекрывает этот метод, должен выполнять это также виртуальным методом, и заголовок должен оставаться идентичным заголовку в самом старшем предке.
Вы получаете определенный выигрыш, он состоит в том, что когда вы обрабатываете метод полиморфно, вызывается правильный виртуальный метод для фактического объектного типа. Это неверно для статических методов: вызов статического метода всегда выполняется для метода, соответствующего объявленному типу экземпляра.
Специальная директива dynamic отсутствует - динамический метод является видом виртуального метода. Поместив в строке объявления метода числовую индексную константу после слова virtual, вы объявляете метод динамическим. В любых потомках этого метода заголовок метода и числовой индекс должны быть идентичны.
Директива virtual может помещаться в определении объекта несколько раз за объявлением любого метода.
Директива private не присоединяется ни к какому полю или методу, но воздействует на все поля и методы, которые следуют за ней. Скрытые поля и методы доступны только внутри метода объекта, в котором они определены, или внутри других подпрограмм либо методов, определенных в секции реализации того же модуля.
ИНКАПСУЛЯЦИЯ
Некоторые объектно-ориентированные языки (например, язык SmallTalk) предписывает строгую форму инкапсуляции: к полям данных объекта невозможно обратиться извне. Если элементом программы извне объекта требуется доступ к этим полям объекта, вы должны создать методы, обеспечивающие такой доступ.
Турбо – Паскаль не требует столь строгого соблюдения инкапсуляции, но в ваших же интересах действовать так, как будто он предписывает это. Вы сами обнаружите, что создаете множество очень коротких методов, подобных тем
НАСЛЕДОВАНИЕ
Концепция наследования проста: люди применяют ее постоянно в обычной речи, чтобы описать что-нибудь новое, используя терминологию чего-то уже известного. Наследование объектов аналогично общепринятому понятию. Когда вы определяете объект потомка в терминах предка, то вы утверждаете, что потомок по большей части такой же, как и предок. Оставшаяся часть объявления описывает различия между ними.
К объекту - потомку в случае необходимости могут быть добавлены новые поля данных. Они не заменяют существующие поля; они просто накапливаются. В потомке могут быть также добавлены новые методы и перекрыты существующие методы. Эти добавления и изменения определяют только, в чем потомок отличается от предка.
Некоторые объектно-ориентированные языки, особенно С++, позволяют многократное наследование. В такой системе объект может иметь больше одного родителя, и иерархия объектов становится направленным циклическим графом, т. е. связи между объектами направлены с ясным различием, кто родитель, а кто порожденный. Набор связей не имеет никакой цикличности - не существует способа проследить маршрут родитель - порожденный и вернуться к объекту, с которого начинали. Однако теперь это уже неясная древовидная структура, в которой объект может иметь самое большое - одного родителя и любое количество порожденных. Таким образом, возникают проблемы повторного наследования. Предположим, что объекты В1 и В2 - потомки объекта А, а объект С наследуется и от В1, и от В2. Очевидно, объект С может наследовать две копии всех полей и методов, которые объекты В1 и В2 унаследовали от А. Любая многократная система наследования порождает подобные проблемы.
Многократное наследование сейчас недопустимо в Турбо Паскале. Возможна ситуация, когда вы хотите создать объектный тип, наследуемый от двух родителей. Есть два варианта обхода ограничения отсутствия многократного наследования. Иногда вы можете сделать одного из двух потенциальных родителей порожденным от другого. Это сработает, если они в основном схожи. Если объекты слишком сильно отстоят друг от друга в иерархии, чтобы сделать один порожденный от другого, рассмотрите создание нового объекта, порожденного от одного потенциального родителя, и добавление другого в качестве поля данных внутри порожденного. Эта методика, которая называется композицией объектов, является довольно обычной практикой - вы найдете ее в OWL. Например, базисный объект Tapplication имеет поле, которое является объектом TwintowsObject.
В общем случае дерево в иерархии объектов развивается от общего к частному. Часто корневой объект иерархии - это ничего не делающий абстрактный объектный тип, определенный для единственной цели - быть корнем иерархии. Объекты - листья в дереве иерархии- объекты без потомков- являются узкоспециализированными, и маршрут от корня до листа увеличивает специализацию объектов. Вы можете обнаружить это в иерархической диаграмме библиотеки OWL.
ПОЛИМОРФИЗМ
Без полиморфизма объектно-ориентированное программирование будет только умным способом приклеивания процедур к полям данных. Этот термин происходит от греческого “ много форм “ - полиморфная ссылка может указывать на определенный объект или на любой объект, унаследованный от него непосредственно или косвенно. Другими словами, полиморфная ссылка объекта может указывать на экземпляр любого объекта в области определенного типа. Вы можете вызывать любой виртуальный метод, который описывается в определенном объектном типе, и будет вызван правильный метод для реального объектного типа. С точки зрения структурного программирования, это кажется невозможным, но объектно-ориентированный Турбо Паскаль выполняет это, используя технологию, которая называется позднее связывание.
Обычный вызов процедуры компилируется в простую команду Call на уровне ассемблера, и после того, как Dos - загрузчик загрузил Exe - файл, адрес вызова остается константой. Это раннее связывание- вызов процедуры связывается с определенным адресом в процессе компиляции.
Вызов виртуального метода происходит совершенно иначе. Это косвенное обращение к адресу, содержащемуся в Таблице Виртуальных Методов (VMT) для определенного объектного типа. Когда вы определяете виртуальный метод для объекта, вы выделяете место в VMT для этого метода, и каждый его потомок будет использовать то же место для его версии метода. Компилятор просто генерирует код для поиска места в VMT и выполняет вызов по найденному там адресу.
Первое слово VMT - размер экземпляра этого объекта, а второе слово используется для проверки инициализации объекта, когда задана директива компилятора.
В каждом потомке данного объекта запись VMT для определенного виртуального метода будет всегда находиться в том же месте VMT. VMT - объекта - потомка начинается так же, как и VMT- предка. Когда потомок перекрывает виртуальный метод, адрес нового метода помещается в соответствующую позицию VMT. Когда потомок добавляет новые виртуальные методы, они добавляются к концу VMT для этого объекта.
Если VMT подобна массиву адресов методов, то DMT подобна разреженному массиву адресов. Вместо того чтобы иметь запись для каждого динамического метода, она содержит только адреса динамических методов, объявленных в текущем объектном типе. Это сокращает размер DMT по сравнению с соответствующей VMT, но означает также, что вызов динамического метода выполняется дольше. Диспетчер динамических методов должен найти требуемый адрес, а не просто извлечь его по известному смещению VMT.
Для обычной процедуры компилятор генерирует код, который непосредственно вызывает адрес процедуры. Для статического метода он помещает адрес экземпляра объекта в стек. Помещение этого адреса в стек инициализирует параметр Self; затем компилятор непосредственно вызывает адрес метода. Сгенерированный код для вызова виртуального метода снова начинается с помещения в стек адреса самого объекта. Первое слово экземпляра этого объектного типа является смещением VMT. Таким образом, таблица виртуальных методов начинается со смещения VMT, поэтому вызов FAR по сохраненному адресу вызывает первый виртуальный метод.
Вызов динамического метода аналогичен вызову виртуального метода до косвенного вызова FAR далее они различаются. Вместо генерации этого вызова компилятор генерирует код, который помещает индекс динамического метода в соответствующий регистр и вызывает диспетчер динамических методов. Диспетчер ищет метод с соответствующим индексом в DMT объекта. Если он не находит такой метод, то прослеживает цепочку DMT предков до тех пор, пока не находит совпадающий индекс; тогда он вызывает метод по соответствующему адресу.
Если объект корня иерархии имеет VMT, то VMT - связь будет первым словом части данных каждого объекта в иерархии. Tobject, корень иерархии OWL, имеет виртуальный метод, поэтому у всех OWL - объектов в этой позиции находится VMT - связь. Полезно узнать, где находится эта связь, и это необходимо сделать в первую очередь, если вы хотите сохранить объект в потомке.
Может показаться, что вызов динамического метода выполняется более медленно, чем вызов статического или виртуального метода. Да, он выполняется медленнее, но вы получите значительный выигрыш - очевидное сокращение размеров кода. Вам не нужно разбираться во внутренних механизмах динамических методов для того, чтобы использовать их. Главное, что вам следует помнить о них это то, что они используют меньше места на объектный тип, чем виртуальные методы, но по времени их вызов выполняется дольше.
ОГРАНИЧЕНИЯ ПОЛИМОРФИЗМА
В языке SmallTalk от объекта к объекту можно отправить запрос на реакцию на вызов любого метода. Объект просматривает список своих методов, проверяя их совпадение с вызванным методом, и если такое совпадение происходит, объект активизирует данный метод. Этот процесс намного медленнее, чем методика VMT или динамический диспетчер сообщений, но зато он многое прощает. В Турбо Паскале нельзя осуществить полиморфный вызов метода, который не определен в заданном объектном типе: компилятор не разрешает этого. Например, обычной практикой является создание связанного списка объектов, содержащего указатели на базовый объект. Этот список может реально содержать любой объект, являющийся потомком базового объекта. Если вы заполнили такой список указателями на различные оконные объекты, описанные в заголовке программы, то можете при желании вызвать любой метод, например, Draw, для каждого элемента. Перед вами стоит проблема - поскольку в базовом объекте нет элемента Draw. Одним из решений является приведение полиморфного объекта к типу первого потомка, в котором определен необходимый метод.
В данном случае это будет образ
Tframe1 (этот пример мы рассматривали на предыдущей лекции).
Имеется более изящное объектно-ориентированное решение. Если вы хотите, чтобы связанный список не содержал ничего, кроме объектов потомка Tframe1, создайте потомок объекта связанного списка, отвечающий этому требованию. Вам все - таки придется выполнить приведение к типу внутри методов вашего объекта - потомка, но вы будете иметь гарантию, что каждый объект в списке находится в области объекта TFrame1.
Говоря о полиморфизме, мы обычно понимали под ним вызов метода объекта, точный тип которого неизвестен. Такое определение выглядит несколько экзотичным, но фактически полиморфные вызовы методов происходят прямо внутри статических методов. Имеются причины для того, чтобы оставлять некоторые методы статическими. Во-первых, интеллектуальный компоновщик может отбросить вызовы неиспользуемых статических методов, а не вызовы неиспользуемых виртуальных методов. Статические вызовы выполняются быстрее и они меньше, и если вы хотите, то можете изменять параметры при перекрытии статического метода. Иногда трудно решить делать ли метод статическим или виртуальным. Когда вы в сомнении, оставьте его статическим - гораздо проще изменить метод на виртуальный ниже в иерархии, чем выполнить обратное действие.
Программирование в среде Windows представляет собой сложную задачу. Это связано с тем, что, во-первых, программа должна иметь архитектуру, управляемую событиями (непривычную для традиционного программирования), а во-вторых, ядро Windows насчитывает более 600 функций и 200 различных сообщений (программисту желательно знать их назначение и применение). Одним из способов упростить программирование является использование объектно-ориентированных библиотек. Одной из таких библиотек является OWL, разработанная фирмой Borland. Новая возможность объектно-ориентированных расширений языков фирмы Borland - динамические виртуальные методы, позволила отказаться от громоздкого оператора выбора, появляющегося в теле подпрограммы обработки событий.
Отметим основные достоинства этой библиотеки:
- последовательный, интуитивно понимаемый и упрощенный интерфейс со средствами, предоставляемые ядром Windows , дает возможность программистам, ранее не знакомым с Windows, создавать приложения, работающие под Windows;
- автоматическая обработка сообщений и управление окнами, минимизирует трудоемкость создания программы;
- возможность повторного использования и расширение кода, позволяющие создавать программы за короткое время с малыми затратами.
Иерархия объектов Object Windows включает объекты, представляющие общие интерфейсные элементы Windows - приложений, такие как окна, панели диалога и элементы управления. Объект представляет собой абстрактный объект, являющийся шаблоном приложения, требуемым идеологией Windows.
Большинство объектов Object Windows представляют собой интерфейсные объекты, экземпляры которых соответствуют реальным интерфейсным элементам. Корнем ветви интерфейсных объектов является абстрактный объект, который определяет общее поведение для всех его потомков.
Производными элементами от TwindowsObject являются Twindow, Tdialog, TControl , которые являются родоначальниками основных групп интерфейсных элементов- окон, панелей диалогов и элементов управления. содержит основной набор методов для всех наследуемых элементов. Каждый конкретный тип объекта переопределяет и дополняет этот набор для обеспечения своего универсального поведения.
Также библиотека содержит объект TApplication
, экземпляр которого выполняет все необходимые действия приложения, включая инициализацию, обработку сообщений, завершения приложения и разрешение ошибочных состояний. Производный объект от инициализирует главное окно с конкретным поведением. Возможно также переопределение рода методов для создания приложения со специфическим поведением.
Стандартные инструментальные объекты решают распространенные специализированные задачи.
Объекты TeditWindow и TFillWindow предназначены для создания редакторов текста, TfileDialog и TinputDialog - для ввода имени файла и текстовой строки. Объекты представляют собой законченный инструментарий, но могут наращивать и видоизменять свои функции за счет создания потомков. Библиотека содержит набор дополнительных объектов общего назначения, используемых в некоторых операциях или самих объектах.
4. ОСНОВНЫЕ ПОНЯТИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННОГО ПОДХОДА. РАЗРАБОТКА ОБЪЕКТНО-ОРИЕНТИРОВАННЫХ ПРОГРАММ
Объектно-ориентированный подход основан на систематическом использовании моделей для языково-независимой разработки программной системы, на основе из ее прагматики.
Последний термин нуждается в пояснении. Прагматика определяется целью разработки программной системы: для обслуживания клиентов банка, для управления работой аэропорта, для обслуживания чемпионата мира по футболу и т.п. В формулировке цели участвуют предметы и понятия реального мира, имеющие отношение к разрабатываемой программной системе (см. рисунок 4.1). При объектно-ориентированном подходе эти предметы и понятия заменяются их моделями, т.е. определенными формальными конструкциями, представляющими их в программной системе.
 |
ее компьютера) и прагматика (смысл программы с точки
зрения ее пользователей)
Модель содержит не все признаки и свойства представляемого ею предмета (понятия), а только те, которые существенны для разрабатываемой программной системы. Тем самым модель "беднее", а, следовательно, проще представляемого ею предмета (понятия). Но главное даже не в этом, а в том, что модель есть формальная конструкция: формальный характер моделей позволяет определить формальные зависимости между ними и формальные операции над ними. Это упрощает как разработку и изучение (анализ) моделей, так и их реализацию на компьютере. В частности, формальный характер моделей позволяет получить формальную модель разрабатываемой программной системы как композицию формальных моделей ее компонентов.
Таким образом, объектно-ориентированный подход помогает справиться с такими сложными проблемами, как
· уменьшение сложности программного обеспечения;
· повышение надежности программного обеспечения;
· обеспечение возможности модификации отдельных компонентов программного обеспечения без изменения остальных его компонентов;
· обеспечение возможности повторного использования отдельных компонентов программного обеспечения.
Систематическое применение объектно-ориентированного подхода позволяет разрабатывать хорошо структурированные, надежные в эксплуатации, достаточно просто модифицируемые программные системы. Этим объясняется интерес программистов к объектно-ориентированному подходу и объектно-ориентированным языкам программирования. Объектно-ориентированный подход является одним из наиболее интенсивно развивающихся направлений теоретического и прикладного программирования.
Объектно-ориентированный подход целесообразно использовать на всех этапах жизненного цикла прикладной программной системы, начиная с анализа требований к программной системе и ее предварительного проектирования, и кончая ее реализацией, тестированием и последующим сопровождением.
Объектно-ориентированный подход имеет два аспекта:
· объектно-ориентированная разработка программного обеспечения;
· объектно-ориентированная реализация программного обеспечения.
4.1. Объектно-ориентированная разработка программ
Объектно-ориентированная разработка программного обеспечения связана с применением объектно-ориентированных моделей при разработке программных систем и их компонентов. Говоря об объектно-ориентированной разработке, я имею в виду:
· объектно-ориентированные методологии (технологии) разработки программных систем;
· инструментальные средства, поддерживающие эти технологии.
Объектно-ориентированная разработка может начаться на самом первом этапе жизненного цикла; она не связана с языком программирования, на котором предполагается реализовать разрабатываемую программную систему: этот язык может и не быть объектно-ориентированным. На этапе разработки объекты - это некоторые формальные конструкции (например, прямоугольники с закругленными углами, с помощью которых они изображаются на схемах), никак пока не связанные с их будущей реализацией на одном из языков программирования.
Объектно-ориентированная разработка программного обеспечения связана с применением объектно-ориентированных методологий (технологий). Обычно эти объектно-ориентированные методологии поддерживаются инструментальными программными средствами, но и без таких средств они полезны, так как позволяют хорошо понять различные аспекты и свойства разрабатываемой программной системы, что в последующем существенно облегчает ее реализацию, тестирование, сопровождение, разработку новых версий и более существенную модификацию.
Нами будут рассмотрены следующие объектно-ориентированные методологии разработки программных систем:
· OMT (Object Modeling Technique)
· SA/SD (Structured Analysis/Structured Design);
· JSD (Jackson Structured Development);
· OSA (Object-Oriented System Analysis).
Наиболее подробно будет рассматриваться объектно-ориентированная методология OMT , которая поддерживает две первые стадии жизненного цикла программных систем. Эта методология выбрана для демонстрации объектно-ориентированного подхода, потому что является одной из наиболее продвинутых и популярных объектно-ориентированных методологий. Более того, ее графический язык (система обозначений для диаграмм) получил достаточно широкое распространение и используется в некоторых других объектно-ориентированных методологиях, а также в большинстве публикаций по объектно-ориентированным методологиям.
Методология OMT поддерживается системой Paradigm+, одной из наиболее известных инструментальных систем объектно-ориентированной разработки.
В технологии OMT проектируемая программная система представляется в виде трех взаимосвязанных моделей:
· объектной модели, которая представляет статические, структурные аспекты системы, в основном связанные с данными;
· динамической модели, которая описывает работу отдельных частей системы;
· функциональной модели, в которой рассматривается взаимодействие отдельных частей системы (как по данным, так и по управлению) в процессе ее работы.
Эти три вида моделей позволяют получить три взаимно-ортогональных представления системы в одной системе обозначений. Совокупность моделей системы может быть проинтерпретирована на компьютере (с помощью инструментального программного обеспечения), что позволяет продемонстрировать заказчику характер работы с будущей системой и существенно упрощает согласование предварительного проекта системы.
4.2. Объектно-ориентированные языки программирования
Реализация программного обеспечения связана с использованием одного из языков программирования. Показано, что наиболее удобными для реализации программных систем, разработанных в рамках объектно-ориентированного подхода, являются объектно-ориентированные языки программирования, хотя возможна реализация и на обычных (не объектно-ориентированных) языках (например, на языке C и на языке Fortran).
Объектно-ориентированные языки программирования пользуются в последнее время большой популярностью среди программистов, так как они позволяют использовать преимущества объектно-ориентированного подхода не только на этапах проектирования и конструирования программных систем, но и на этапах их реализации, тестирования и сопровождения.
Первый объектно-ориентированный язык программирования Simula 67 был разработан в конце 60-х годов в Норвегии.
Авторы этого языка очень точно угадали перспективы развития программирования: их язык намного опередил свое время. Однако современники (программисты 60-х годов) оказались не готовы воспринять ценности языка Simula 67, и он не выдержал конкуренции с другими языками программирования (прежде всего, с языком Fortran). Прохладному отношению к языку Simula 67 способствовало и то обстоятельство, что он был реализован как интерпретируемый (а не компилируемый) язык, что было совершенно неприемлемым в 60-е годы, так как интерпретация связана со снижением эффективности (скорости выполнения) программ.
Но достоинства языка Simula 67 были замечены некоторыми программистами, и в 70-е годы было разработано большое число экспериментальных объектно-ориентированных языков программирования: например, языки CLU, Alphard, Concurrent Pascal и др. Эти языки так и остались экспериментальными, но в результате их исследования были разработаны современные объектно-ориентированные языки программирования: C++, Smalltalk, Eiffel и др.
Наиболее распространенным объектно-ориентированным языком программирования, безусловно, является C++. Свободно распространяемые коммерческие системы программирования C++ существуют практически на любой платформе.
Разработка новых объектно-ориентированных языков программирования продолжается. С 1995 года стал широко распространяться новый объектно-ориентированный язык программирования Java, ориентированный на сети компьютеров и, прежде всего, на Internet. Синтаксис этого языка напоминает синтаксис языка C++, однако, эти языки имеют мало общего. Java интерпретируемый язык: для него определены внутреннее представление (bytecode) и интерпретатор этого представления, которые уже сейчас реализованы на большинстве платформ. Интерпретатор упрощает отладку программ, написанных на языке Java, обеспечивает их переносимость на новые платформы и адаптируемость к новым окружениям. Он позволяет исключить влияние программ, написанных на языке Java, на другие программы и файлы, имеющиеся на новой платформе, и тем самым обеспечить безопасность при выполнении этих программ.
Эти свойства языка Java позволяют использовать его как основной язык программирования для программ, распространяемых по сетям (в частности, по сети Internet).
4.3. Методология
SA/SDМетодология SA/SD (Structured Analysis/Structured Design) содержит несколько вариантов систем обозначений для формальной спецификации программных систем. На этапе анализа требований и предварительного проектирования для логического описания проектируемой системы используются спецификации (формальные описания) процессов, словарь данных, диаграммы потоков данных, диаграммы состояний и диаграммы зависимостей объектов.
Диаграммы потоков данных, составляющие основу методологии SA/SD, моделируют преобразования данных при их прохождении через систему. Методология SA/SD состоит в последовательном рассмотрении процессов, входящих в состав ДПД, с представлением каждого процесса через ДПД, содержащую в своем составе более простые процессы. Эта процедура представления более сложных процессов через ДПД начинается с ДПД всей системы и заканчивается, когда все полученные ДПД содержат достаточно элементарные процессы. Для каждого процесса самого нижнего уровня составляется спецификация; спецификация описывается с помощью псевдокода, таблиц принятия решений и т.п.
Детали, не учтенные в наборе ДПД, содержатся в словаре данных, который определяет потоки и хранилища данных, а также семантику различных имен.
Набор диаграмм состояния процессов играет ту же роль, что и динамическая модель в методологии OMT.
Диаграммы зависимостей объектов отражают зависимости между хранилищами данных. Эти диаграммы аналогичны объектной модели методологии OMT.
Так в методологии SA/SD организован этап структурного анализа (SA). После структурного анализа начинается этап структурного конструирования (SD), в процессе которого разрабатываются и уточняются более тонкие детали проектируемой системы.
Но в методологии SA/SD ведущей является функциональная модель (набор ДПД), на втором месте по важности стоит динамическая модель и на последнем месте - объектная модель.
Таким образом, в методологии SA/SD проектируемая система описывается с помощью процедур (процессов), что несколько противоречит объектно- ориентированному подходу. Методология OMT гораздо ближе к нему: в ней моделирование концентрируется вокруг объектной модели, т.е. вокруг объектов, из которых строится проектируемая система.
Процедурная ориентированность методологии SA/SD является ее недостатком: системы, спроектированные по этой методологии, имеют менее четкую структуру, так как разбиение процесса на подпроцессы во многом произвольно, зависит от реализации и плохо отражает структуру проектируемой системы.
В то же время методология SA/SD является одним из первых хорошо продуманных формальных подходов к разработке программных систем.
4.4. Методология
JSDМетодология JSD (Jackson Structured Development) предлагает свой стиль разработки программных систем; он отличается от стиля, принятого в методологиях SA/SD или OMT. Методология JSD, разработанная Майклом Джексоном в середине 80-х годов, особенно популярна в Европе. В методологии JSD не делается различий между этапом анализа требований к системе и этапом ее разработки; оба этапа объединяются в один общий этап разработки спецификаций проектируемой системы. На этом этапе решается вопрос "что должно быть сделано"; вопрос "как это должно быть сделано" решается на следующем этапе - этапе реализации системы. Методология JSD часто применяется для проектирования систем реального времени.
Как и другие методологии, методология JSD использует систему графических обозначений, хотя эта методология и менее ориентирована на графику, чем методологии SA/SD и OMT.
Разработка модели JSD начинается с изучения объектов реального мира. Целью системы является обеспечение требуемой функциональности, но Джексон понимает, что сначала следует убедиться, что эта функциональность согласуется с реальным миром. Модель JSD описывает реальный мир в терминах сущностей (объектов), действий и порядка выполнения действий.
Разработка системы по методологии JSD включает следующие шесть фаз:
· разработка действий и объектов;
· разработка структуры объектов;
· разработка исходной модели;
· разработка функций;
· разработка временных ограничений;
· реализация системы.
На фазе разработки действий и объектов разработчик, руководствуясь внешними требованиями к проектируемой системе, составляет перечень сущностей (объектов) и действий реального мира, связанных с этой системой. Так, например, проектируя систему управления двумя лифтами в шестиэтажном доме, можно выделить два объекта "лифт" и "кнопка" и три действия - "нажатие кнопки", "лифт приходит на этаж n" и "лифт покидает этаж n". И объекты, и действия взяты из реального мира, а не искусственно введены в рассмотрение проектировщиком. Все действия являются атомарными (неразложимыми на поддействия) и происходят в фиксированные моменты времени.
На фазе разработки структуры объектов действия каждого объекта частично упорядочиваются во времени. Так, в рассматриваемом примере действия "лифт приходит на этаж n" и "лифт покидает этаж n" должны чередоваться: два действия "лифт приходит на этаж n" не могут идти одно за другим.
Фаза разработки исходной модели связывает реальный мир с абстрактной моделью, устанавливая соответствие между вектором состояния и потоком данных. Вектор состояния обеспечивает "развязку" по управлению; так в примере с лифтами первая же нажатая кнопка вверх установит значение переключателя (флажка) "вверх" после чего лифт не будет реагировать на дальнейшие нажатия кнопок вверх, так что нажатие кнопки вверх один или пять раз приведет к одинаковому результату.
Аналогично, поток данных позволяет обеспечить "развязку" по данным: примером может служить буфер файла.
На фазе разработки функций с помощью специального псевдокода устанавливаются выходные данные каждого действия. Для системы управления лифтами примером функции является переключение лампочек на панели лифта при прибытии лифта на очередной этаж.
На фазе разработки временных ограничений решается вопрос о допустимых временных отклонениях системы от реального мира. В результате получается множество временных ограничений. В примере с лифтами одним из временных ограничений будет решение вопроса о том, как долго нужно нажимать на кнопку лифта, чтобы добиться его реакции.
Наконец, на фазе реализации системы решаются проблемы управления процессами и распределения процессов по процессорам.
Методология JSD может быть названа объектно-ориентированной с большой натяжкой: в ней почти не рассматривается структура объектов, мало внимания уделяется их атрибутам.
Тем не менее, методология JSD может успешно применяться для проектирования и реализации следующих типов прикладных программных систем:
· Параллельные асинхронные программные системы, в которых процессы могут взаимно синхронизировать друг друга.
· Программные системы реального времени; методология JSD ориентирована именно на такие системы.
· Программные системы для параллельных компьютеров; парадигма, принятая в методологии JSD может здесь оказаться полезной.
Методология JSD плохо приспособлена для решения следующих проблем:
· Высокоуровневый анализ: методология JSD не обеспечивает широкого понимания проблемы; она неэффективна для абстракции и упрощения проблем.
· Разработка баз данных: это слишком сложная проблема для методологии JSD.
4.5. Методология
OSAМетодология OSA (Object-Oriented System Analysis) обеспечивает объектно-ориентированный анализ программных систем и не содержит возможностей, связанных с поддержкой этапа разработки.
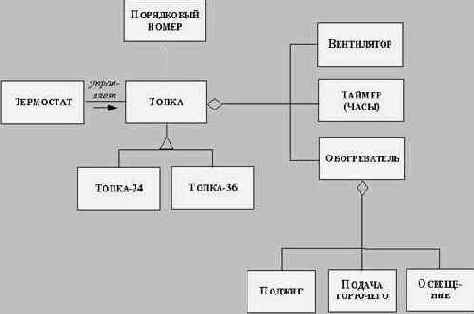 |
Рис. 4.2. Модель зависимостей между объектами для системы
управления топкой в теплоцентрали
Методология OSA сосредоточена только на проблемах анализа, предлагая ряд интересных соображений, связанных с объектно-ориентированным анализом систем и специально исключая из рассмотрения особенности, характерные для разработки. Предлагая удобные и тонкие методы анализа систем, методология OSA обеспечивает интерпретацию моделей на компьютере на самых ранних этапах анализа системы: OSA реализована в системе программирования C++ на рабочей станции Hewlett-Packard 700 под управлением ОС HP-UX 9.01.
Методология OSA, как и другие методологии, поддерживает три взаимно-ортогональных представления (модели) проектируемой системы:
· модель зависимостей между объектами;
· модель поведения объектов;
· модель взаимодействия объектов.
Модель зависимостей между объектами аналогична объектной модели методологии OMT. В ней рассматриваются объекты, множества отношений между объектами и различные ограничения. Для ее представления используются диаграммы
Модель поведения объектов представляет собой набор диаграмм состояний объектов: на этих диаграммах изображаются состояния объектов, переходы между состояниями, исключительные ситуации и ограничения, связанные с реальным временем.
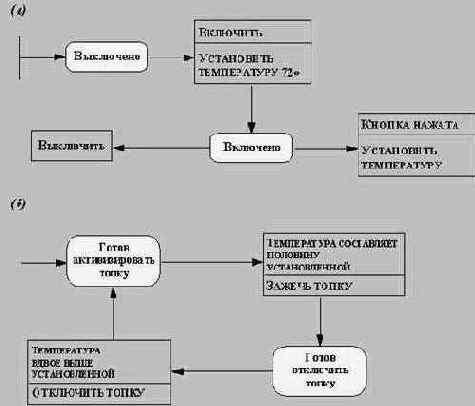 |
Модель взаимодействия объектов - это набор представлений проектируемой системы, на которых показаны взаимодействия объектов между собой и с окружением системы.
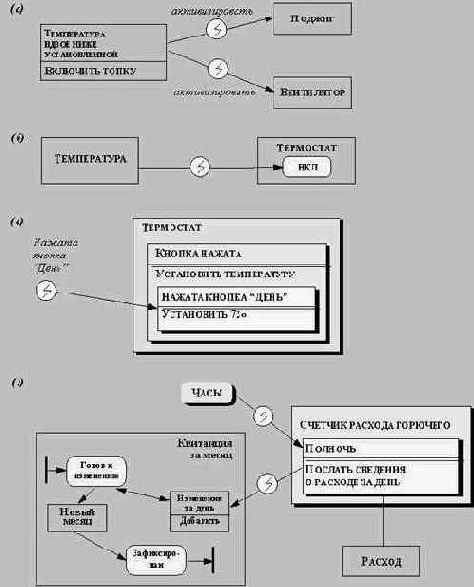 |
Интерпретация и анализ представлений (моделей) проектируемой системы позволяет полностью формализовать описания объектов и получить строгую формальную спецификацию проектируемой системы до начала ее разработки (см. рис. 4.5).
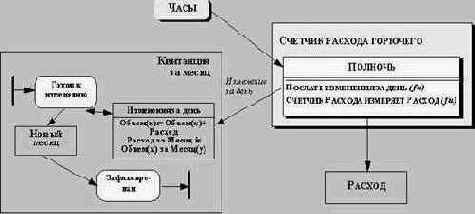 |
методологии OSA
4.6. Методология
OMTМетодология OMT (Object Modeling Technique), поддерживает две первые стадии разработки программных систем. Эта методология опирается на программный продукт OMTTool, который позволяет разрабатывать модели проектируемой программной системы в интерактивном режиме с использованием многооконного графического редактора и интерпретатора наборов диаграмм, составляемых при анализе требований к системе и ее проектировании с использованием методологии OMT. Таким образом, как только получен достаточно полный набор диаграмм проектируемой программной системы, его можно проинтерпретировать и предварительно оценить различные свойства будущей реализации системы. В настоящее время OMTTool
входит в состав системы Paradigm+.
Далее рассмотрим построение моделей технологии OMT подробно.
Первая фаза жизненного цикла - анализ требований и предварительное проектирование системы. Объектно-ориентированное моделирование
Как известно, проектирование прикладной программной системы начинается с анализа требований, которым она должна будет удовлетворять. Такой анализ проводится с целью понять назначение и условия эксплуатации системы настолько, чтобы суметь составить ее предварительный проект.
При объектно-ориентированном подходе анализ требований к системе сводится к разработке моделей этой системы. Моделью системы (или какого-либо другого объекта или явления) мы называем формальное описание системы, в котором выделены основные объекты, составляющие систему, и отношения между этими объектами. Построение моделей - широко распространенный способ изучения сложных объектов и явлений.
В модели опущены многочисленные детали, усложняющие понимание. Моделирование широко распространено и в науке, и в технике.
Модели помогают:
· проверить работоспособность разрабатываемой системы на ранних этапах ее разработки;
· общаться с заказчиком системы, уточняя его требования к системе;
· вносить (в случае необходимости) изменения в проект системы (как в начале ее проектирования, так и на других фазах ее жизненного цикла).
В настоящее время существует несколько технологий объектно-ориентированной разработки прикладных программных систем, в основе которых лежит построение и интерпретация на компьютере моделей этих систем. Мы подробно ознакомимся с одной из таких технологий - OMT. Эта технология оказала большое влияние на других разработчиков объектно-ориентированных технологий, а книга, в которой она описана, является одной из наиболее часто цитируемых книг по данному направлению. Более того, система обозначений (графический язык) для описания моделей, предложенная в этой книге, широко применяется в других технологиях и в статьях по объектно-ориентированной разработке программных систем.
Как вы уже знаете в технологии OMT, проектируемая программная система представляется в виде трех взаимосвязанных моделей: объектной, динамической, функциональной модели.
Модели, разработанные и отлаженные на первой фазе жизненного цикла системы, продолжают использоваться на всех последующих его фазах, облегчая программирование системы, ее отладку и тестирование, сопровождение и дальнейшую модификацию.
Как будет показано в дальнейшем, модели системы не связаны с языком программирования, на котором будет реализована система.
4.7. Объектная модель системы
Объектная модель описывает структуру объектов, составляющих систему, их атрибуты, операции, взаимосвязи с другими объектами. В объектной модели должны быть отражены те понятия и объекты реального мира, которые важны для разрабатываемой системы.
В объектной модели отражается, прежде всего, прагматика разрабатываемой системы, что выражается в использовании терминологии прикладной области, связанной с использованием разрабатываемой системы.
4.8. Объекты и классы
Объекты
По определению будем называть объектом понятие, абстракцию или любую вещь с четко очерченными границами, имеющую смысл в контексте рассматриваемой прикладной проблемы. Введение объектов преследует две цели:
· понимание прикладной задачи (проблемы);
· введение основы для реализации на компьютере.
Примеры объектов: форточка, Банк "Империал", Петр Сидоров, дело № 7461, сберкнижка и т.д.
Цель разработки объектной модели - описать объекты, составляющие в совокупности проектируемую систему, а также выявить и указать различные зависимости между объектами. Декомпозиция проблемы на объекты - творческий, плохо формализуемый процесс.
Все объекты могут быть отличены один от другого: пусть у нас есть два яблока, имеющие одинаковый цвет, форму, вес и вкус; все равно это два яблока (а не одно), в чем легко убедиться, съев одно из них (другое останется). Между объектами можно установить отношение тождества: объекты, удовлетворяющие этому отношению, одинаковы (тождественны), как вышеупомянутые яблоки. В случае с яблоками иногда говорят о двух экземплярах объекта яблоко. Мы будем считать здесь, что объект и экземпляр объекта - это одно и то же.
Классы
Два яблока из предыдущего примера принадлежат одному и тому же классу объектов (именно с этим связана их одинаковость). Цвет, форма, вес и вкус яблока - это его атрибуты: совокупность атрибутов и их значений (например, красное, овальное, стограммовое, кисло-сладкое) характеризует объект.
Все объекты одного и того же класса характеризуются одинаковыми наборами атрибутов. Однако объединение объектов в классы определяется не наборами атрибутов, а семантикой.
Так, например, объекты конюшня и лошадь могут иметь одинаковые атрибуты: цена и возраст. При этом они могут относиться к одному классу, если рассматриваются в задаче просто как товар, либо к разным классам, что более естественно.
 |
Объединение объектов в классы позволяет ввести в задачу абстракцию и рассмотреть ее в более общей постановке. Класс имеет имя (например, лошадь), которое относится ко всем объектам этого класса. Кроме того, в классе вводятся имена атрибутов, которые определены для объектов. В этом смысле описание класса аналогично описанию типа структуры (записи); при этом каждый объект имеет тот же смысл, что и экземпляр структуры (переменная или константа соответствующего типа). Пример класса и объекта этого класса приведен на рисунке выше.
Атрибуты объектов
Атрибут - это значение, характеризующее объект в его классе. Примеры атрибутов: категория, баланс, кредит (атрибуты объектов класса счет); имя, возраст, вес (атрибуты объектов класса человек) и т.д.
Среди атрибутов различаются постоянные атрибуты (константы) и переменные атрибуты. Постоянные атрибуты характеризуют объект в его классе (например, номер счета, категория, имя человека и т.п.). Текущие значения переменных атрибутов характеризуют текущее состояние объекта (например, баланс счета, возраст человека и т.п.); изменяя значения этих атрибутов, мы изменяем состояние объекта.
Атрибуты перечисляются во второй части прямоугольника, изображающего класс (см. предыдущий рисунок). Иногда указывается тип атрибутов (ведь каждый атрибут - это некоторое значение) и начальное значение переменных атрибутов (совокупность начальных значений этих атрибутов задает начальное состояние объекта).
Следует отметить, что, говоря об объектах и их классах, мы не подразумеваем никакого объектно-ориентированного языка программирования. Это, в частности, выражается в том, что на данном этапе разработки программной системы следует рассматривать только такие атрибуты, которые имеют смысл в реальности (все атрибуты объектов класса счет – см.
предыдущий рисунок - обладают этим свойством). Атрибуты связаны с особенностями общей реализации. Например, если известно, что будет использоваться база данных, в которой каждый объект имеет уникальный идентификатор, то включать этот идентификатор в число атрибутов объекта на данном этапе не следует. Дело в том, что, вводя такие атрибуты, мы ограничиваем возможности реализации системы. Так, вводя в качестве атрибута уникальный идентификатор объекта в базе данных, мы уже в самом начале проектирования отказываемся от использования СУБД, которые такой идентификатор не поддерживают.
Операции и методы
Операция - это функция (или преобразование), которую можно применять к объектам данного класса. Примеры операций: проверить, снять, поместить (для объектов класса счет – см. предыдущий рисунок),
Все объекты данного класса используют один и тот же экземпляр каждой операции (т.е. увеличение количества объектов некоторого класса не приводит к увеличению количества загруженного программного кода). Объект, из которого вызвана операция, передается ей в качестве ее неявного аргумента (параметра).
Одна и та же операция может, вообще говоря, применяться к объектам разных классов: такая операция называется полиморфной, так как она может иметь разные формы для разных классов. Например, для объектов классов вектор и комплексное_число можно определить операцию +; эта операция будет полиморфной, так как сложение векторов и сложение комплексных чисел, вообще говоря, разные операции.
Каждой операции соответствует метод - реализация этой операции для объектов данного класса. Таким образом, операция - это спецификация метода, метод - реализация операции. Например, в классе файл может быть определена операция печать (print). Эта операция может быть реализована разными методами: (а) печать двоичного файла; (б) печать текстового файла и др. Логически эти методы выполняют одну и ту же операцию, хотя реализуются они разными фрагментами кода.
Каждая операция имеет один неявный аргумент - объект, к которому она применяется.
Кроме того, операция может иметь и другие аргументы (параметры). Эти дополнительные аргументы параметризуют операцию, но не связаны с выбором метода. Метод связан только с классом и объектом (некоторые объектно-ориентированные языки, например C++, допускают одну и ту же операцию с разным числом аргументов, причем, используя то или иное число аргументов, мы практически выбираем один из методов, связанных с такой операцией; на этапе предварительного проектирования системы удобнее считать эти операции различными, давая им разные имена, чтобы не усложнять проектирование).
Операция (и реализующие ее методы) определяется своей сигнатурой, которая включает, помимо имени операции, типы (классы) всех ее аргументов и тип (класс) результата (возвращаемого значения). Все методы, реализующие операцию должны иметь такую же сигнатуру, что и реализуемая ими операция.
Операции перечисляются в третьей части прямоугольника (см. предыдущий рисунок), описывающего класс. Каждая операция должна быть представлена своей сигнатурой, однако на ранних стадиях проектирования можно ограничиваться указанием имени операции, отложив полное определение сигнатуры на конец рассматриваемой фазы жизненного цикла (либо даже на последующие фазы). В графическом языке технологии OMT тип любого объекта данных указывается вслед за именем этого объекта после двоеточия (как в языке Паскаль).
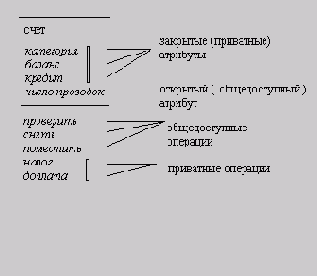 |
Рис. 4.7. Открытые и закрытые атрибуты и операции
Значения некоторых атрибутов объекта могут быть доступны только операциям этого объекта. Такие атрибуты называются закрытыми. На следующем рисунке показаны закрытые атрибуты для объектов класса счет. Значения закрытых атрибутов объекта можно узнать вне объекта только в том случае, если среди операций этого объекта определены соответствующие запросы.
Аналогично, в объекте можно определить и закрытые (вспомогательные) операции, однако на ранних стадиях проектирования этого, как правило, не делают, так как выделение закрытых операций связано, в основном, с реализацией системы.
Запросы без аргументов (за исключением неявного аргумента - объекта, к которому применяется операция) могут рассматриваться как производные атрибуты. Значения производных атрибутов зависят от значений основных атрибутов. В этом их отличие от основных атрибутов, значения которых независимы. Следовательно, значения основных атрибутов объекта определяют как его состояние, так и значения его производных атрибутов. Так, например, длина, ширина и высота комнаты - ее основные атрибуты, а площадь и кубатура - производные атрибуты; такой атрибут как кубатура нужен для того, чтобы не вычислять кубатуру комнаты всякий раз, когда понадобится ее значение.
Выбор основных атрибутов объектов произволен, но в число основных атрибутов не следует включать такие атрибуты, значения которых определяются значениями других атрибутов, так что на самом деле они являются производными.
Таким образом, для задания класса необходимо указать имя этого класса, а затем перечислить его атрибуты и операции (или методы). Полное описание объекта на графическом языке OMT имеет вид, изображенный на следующем рисунке. Однако иногда удобно бывает пользоваться сокращенным описанием класса, когда в прямоугольнике, изображающем этот класс, указывается только имя класса.
|
ИМЯ_КЛАССА |
|
имя_атрибута 1: тип_1 = значение_по_умолчанию_1 имя_атрибута 2: тип_2 = значение_по_умолчанию_2 . . . . . . . . . . . . . . . |
|
имя_операции_1 (список_аргументов_1): тип_результата сигнатура_операции_2 сигнатура_операции_3 . . . . . . . . . . . . . . . . |
Рис. 4.8. Полное представление объекта в OMT
Зависимости между классами (объектами)
С каждым объектом связана структура данных, полями которой являются атрибуты этого объекта и указатели функций (фрагментов кода), реализующих операции этого объекта (отметим, что указатели функций в результате оптимизации кода обычно заменяются на обращения к этим функциям).
Таким образом, объект - это некоторая структура данных, тип которой соответствует классу этого объекта.
Между объектами можно устанавливать зависимости по данным. Эти зависимости выражают связи или отношения между классами указанных объектов. Примеры таких зависимостей изображены на следующем рисунке (первые две зависимости - бинарные, третья зависимость - тренарная). Зависимость изображается линией, соединяющей классы, над которой надписано имя этой зависимости, или указаны роли объектов (классов) в этой зависимости (указание ролей - наиболее удобный способ идентификации зависимости).
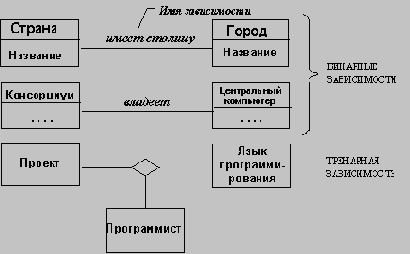 |
Зависимости между классами
Зависимости между классами являются двусторонними: все классы в зависимости равноправны. Это так даже в тех случаях, когда имя зависимости как бы вносит направление в эту зависимость. Так, в первом примере на рисунке имя зависимости имеет_столицу предполагает, что зависимость направлена от класса страна к классу город (двусторонность зависимости вроде бы пропала); но следует иметь в виду, что эта зависимость двусторонняя в том смысле, что одновременно с ней существует и обратная зависимость является_столицей. Точно таким же образом, во втором примере на рисунке можно рассматривать пару зависимостей владеет-принадлежит. Подобных недоразумений можно избежать, если идентифицировать зависимости не по именам, а по наименованиям ролей классов, составляющих зависимость.
В языках программирования зависимости между классами (объектами) обычно реализуются с помощью ссылок (указателей) из одного класса (объекта) на другой. Представление зависимостей с помощью ссылок обнаруживает тот факт, что зависимость является свойством пары классов, а не какого-либо одного из них, т.е. зависимость - это отношение. Отметим, что хотя зависимости между объектами двунаправлены, их не обязательно реализовать в программах как двунаправленные, оставляя ссылки лишь в тех классах, где это необходимо для программы.
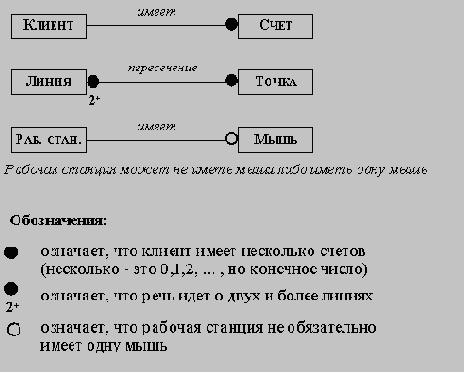 |
Первый пример показывает зависимость между клиентом банка и его счетами. Клиент банка может иметь одновременно несколько счетов в этом банке, либо вовсе не иметь счета (когда он впервые становится клиентом банка). Таким образом, нужно изобразить зависимость между клиентом и несколькими счетами, что и сделано на рисунке. Второй пример показывает зависимость между пересекающимися кривыми (в частности, прямыми) линиями. Можно рассматривать 2, 3, и более таких линий, причем они могут иметь несколько точек пересечения. Наконец, третий пример показывает необязательную (optional) зависимость: компьютер может иметь, а может и не иметь мышь.
Рис. 4.10
Дальнейшие примеры зависимостей. Обозначения
Зависимостям между классами соответствуют зависимости между объектами этих классов. На последующих рисунках показаны зависимости между объектами для примеров, изображенных на предыдущих рисунках.
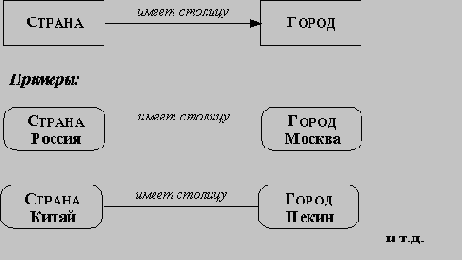 |
Отметим, что при изображении зависимостей между объектами мы, как правило, знаем количество объектов и не нуждаемся в таких обозначениях как "несколько", "два и более", "не обязательно".
При проектировании системы удобнее оперировать не объектами, а классами.
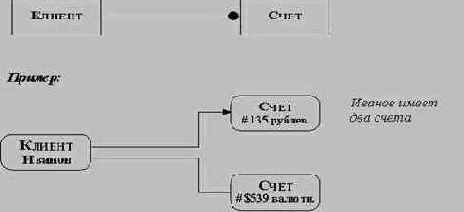 |
Понятие зависимости перенесено в объектно-ориентированную технологию проектирования программных систем из технологии проектирования (и моделирования) баз данных, где зависимости используются с давних пор. Языки программирования, как правило, не поддерживают явного описания зависимостей. Тем не менее, описание зависимостей очень полезно при разработке программных систем. Технология OMT использует зависимости при интерпретации диаграмм, описывающих систему.
Атрибуты зависимостей
 |
следующий рисунок, на котором атрибут зависимости обозначается прямоугольником, связанным дугой с прямой, изображающей зависимость. Такое обозначение атрибутов зависимостей принято в технологии OMT. Отметим, что разрешение на доступ связано как с пользователем, так и с файлом, и не может быть атрибутом ни пользователя, ни файла в отдельности.
Рис. 4.13. Пример атрибута зависимости
 |
Рис. 4.14. Атрибуты двух зависимостей между одним и многими
Иногда зависимости, имеющие много атрибутов, представляют с помощью классов. Такие зависимости в базах данных представляются временными таблицами, организуемыми в процессе обращения с базой данных. Пример зависимости, представленной через класс, показана на следующем рисунке, на котором представлена информация о регистрации пользователей на рабочих станциях.
 |
Рис. 4.15. Представление зависимости в виде класса
Имена ролей
Роль определяет одну сторону зависимости. В бинарной зависимости определены две роли. Имя роли однозначно определяет одну сторону зависимости. Роли дают возможность рассматривать бинарную зависимость как связь между объектом и множеством зависимых объектов: каждая роль является обозначением объекта или множества объектов, связанных зависимостью с объектом на другом конце зависимости.
Имя роли можно рассматривать как производный атрибут, множеством значений которого является множество связанных с этой ролью объектов. В бинарной зависимости пара имен ролей может использоваться для идентификации этой зависимости.
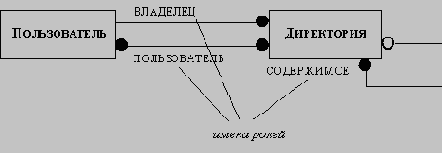 |
Пользователь может быть либо владельцем, либо зарегистрированным пользователем директории; директория может содержать в себе другие директории.
Имена ролей следует обязательно указывать в тех случаях, когда зависимость устанавливается между объектами одного и того же класса (как в случаях, показанных на предыдущих рисунках). Имена ролей должны быть уникальны, так как они используются для различения объектов, участвующих в зависимости.
Агрегация
Агрегация - это зависимость между классом составных объектов и классами, представляющими компоненты этих объектов (отношение "целое"-"часть"). Агрегация обозначается ромбиком: на следующем рисунке приведен пример агрегации; этот пример интерпретируется следующим образом: документ состоит из нескольких (нуля, или более) абзацев; каждый абзац состоит из нескольких (нуля, или более) предложений.
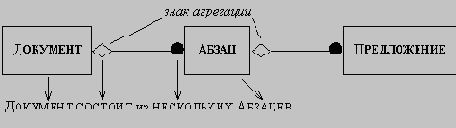 |
Наиболее важным свойством отношения агрегации является его транзитивность (если A есть часть B, а B есть часть C, то A есть часть C): так, из рисунка можно заключить, что документ состоит из нескольких (нуля, или более) предложений. Легко видеть, что отношение агрегации антисимметрично (если A есть часть B, то B не есть часть A). Отметим также, что часть свойств целого может быть перенесена и на его части, возможно, с несущественными изменениями (например, контекст каждого оператора некоторой функции совпадает с внутренним контекстом всей функции).
Дальнейшие примеры агрегации показаны на следующем рисунке. Отметим, что обе агрегации, показанные на рисунке (а), следует рассматривать не как зависимости между пятерками классов, а как четверки зависимостей между парами классов. Только при таком рассмотрении можно говорить о транзитивности и антисимметричности отношения агрегации.
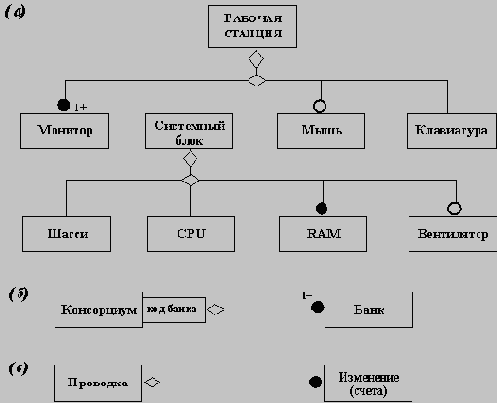 |
Обобщение и наследование
Обобщение и наследование позволяют выявить аналогии между различными классами объектов, определяют многоуровневую классификацию объектов. Так, в графических системах могут существовать классы, определяющие обрисовку различных геометрических фигур: точек, линий (прямых, дуг окружностей и кривых, определяемых сплайнами), многоугольников, кругов и т.п.
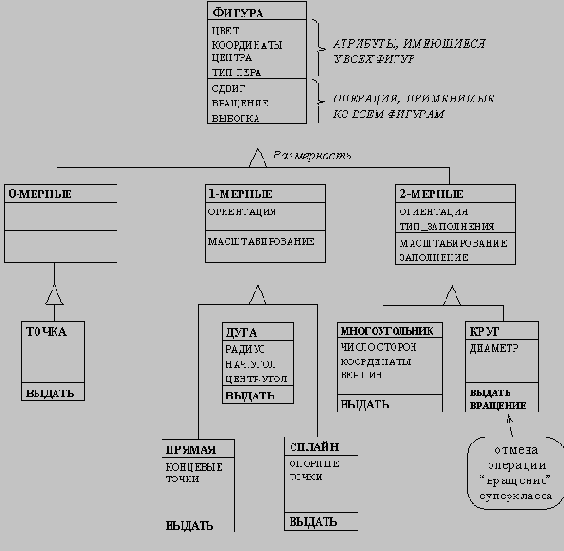
Рис. 4.19. Обобщение (выделение суперклассов)
Обобщение позволяет выделить класс одномерные фигуры и считать классы прямая, дуга и сплайн подклассами класса одномерные фигуры, а класс одномерные фигуры - суперклассом классов прямая, дуга и сплайн. Если при этом принять соглашение, что атрибуты и операции суперкласса действительны в каждом из его подклассов (говорят, что эти атрибуты и операции наследуются подклассами), то одинаковые атрибуты и операции классов прямая, дуга и сплайн (подклассов) могут быть вынесены в класс одномерные фигуры (суперкласс). Аналогично можно поступить и с двумерными фигурами, определив для классов многоугольник и круг суперкласс двумерная фигура. Наконец, можно определить класс фигура как суперкласс классов нульмерная фигура, одномерная фигура и двумерная фигура. Легко видеть, что отношения "подкласс - суперкласс" (обобщение) и "суперкласс - подкласс" (наследование) транзитивны, что позволяет строить классификационные деревья. При этом атрибуты и операции каждого суперкласса наследуются его подклассами всех уровней (мы как бы выносим за скобки одинаковые операции). Это значительно облегчает и сокращает описание классов.
На схемах обобщение (наследование) изображается треугольником. Треугольник следует ставить даже в том случае, когда суперкласс имеет всего один подкласс. Слово размерность, следующее за верхним треугольником на рисунке, является дискриминатором.
Дискриминатор - это атрибут типа "перечисление", показывающий, по какому из свойств объектов сделано данное обобщение.
Необходимо отметить, что, как показывает опыт практического проектирования систем, следует избегать обширных многоуровневых классификаций, так как поведение подклассов низших уровней многоуровневой классификации бывает трудно понять: большая часть (а нередко и все) атрибутов и операций таких классов определена в их суперклассах различных уровней. Если количество уровней классификации стало непомерно большим, нужно слегка изменить структурирование системы. Чтобы понять, какое число уровней является непомерно большим, можно руководствоваться следующими оценками: два-три уровня наследования, как правило, приемлемы всегда (мне известна одна фирма, разрабатывающая программные системы, в которой издан стандарт фирмы, запрещающий более чем трехуровневые классификации в программах); десятиуровневая классификация почти всегда неприемлема; пять-шесть уровней, как правило, достаточно для программистов и не слишком обременяет администрацию.
Обобщение и наследование широко применяются не только при анализе требований к программным системам и их предварительном проектировании, но и при их реализации.
Иногда в подклассе бывает необходимо переопределить операцию, определенную в одном из его суперклассов. Для этого операция, которая может быть получена из суперкласса в результате наследования, определяется и в подклассе; это ее повторное определение "заслоняет" ее определение в суперклассе, так что в подклассе применяется не унаследованная, а переопределенная в нем операция. Напомним, что каждая операция определяется своей сигнатурой; следовательно, сигнатура переопределения операции должна совпадать с сигнатурой операции из суперкласса, которая переопределяется данной операцией. Так, в примере, изображенном на предыдущем рисунке, в классе круг переопределяется операция вращение его суперкласса фигура (при повороте круга его изображение не меняется, что позволяет сделать операцию вращение в классе круг пустой).
Переопределение может преследовать одну из следующих целей:
· расширение: новая операция расширяет унаследованную операцию, учитывая влияние атрибутов подкласса;
· ограничение: новая операция ограничивается выполнением лишь части действий унаследованной операции, используя специфику объектов подкласса;
· оптимизация: использование специфики объектов подкласса позволяет упростить и ускорить соответствующий метод;
· удобство.
Целесообразно придерживаться следующих семантических правил наследования:
· все операции-запросы (операции, которые используют значения атрибутов, но не изменяют их) должны наследоваться всеми подклассами;
· все операции, изменяющие значения атрибутов, должны наследоваться во всех их расширениях; • все операции, изменяющие значения ограниченных атрибутов, или атрибутов, определяющих зависимости, должны блокироваться во всех их расширениях (например, операция размер_по_оси_x естественна для класса эллипс, но должна быть заблокирована (заменена пустой операцией) в его подклассе круг);
· операции не следует переопределять коренным образом; все методы, реализующие одну и ту же операцию, должны осуществлять сходное преобразование атрибутов;
· унаследованные операции можно уточнять, добавляя дополнительные действия.
Следуя этим правилам, которые, к сожалению, редко поддерживаются объектно-ориентированными языками программирования, можно сделать разрабатываемую программу более понятной, легче модифицируемой, менее подверженной влиянию различных ошибок и недосмотров.
Абстрактные классы
Суперкласс, в котором заданы только атрибуты и сигнатуры операций, но не определены методы, реализующие его операции, называется абстрактным классом.
Методы, реализующие операции абстрактного класса, определяются в его подклассах, которые называются конкретными классами.
Абстрактный класс не может иметь объектов, так как в нем не определены операции над объектами; объекты должны принадлежать конкретным подклассам абстрактного класса. Абстрактные классы используются для спецификации интерфейсов операций (методы, реализующие эти операции, впоследствии определяются в подклассах абстрактного класса). Абстрактные классы удобны на фазе анализа требований к системе, так как они позволяют выявить аналогию в различных, на первый взгляд, операциях, определенных в анализируемой системе.
Множественное наследование
Множественное наследование позволяет классу иметь более одного суперкласса, наследуя свойства (атрибуты и операции) всех своих суперклассов. Класс, имеющий несколько суперклассов, называется объединенным классом. Свойства класса-предка, встречающегося более чем один раз, в графе наследования, наследуются только в одном экземпляре. Конфликты между параллельными определениями порождают двусмысленности, которые должны разрешаться во время реализации. На практике следует избегать таких двусмысленностей или плохого понимания даже в тех случаях, когда конкретный язык программирования, выбранный для реализации системы, предоставляет возможность их разрешения, используя приоритеты или какие-либо другие средства.
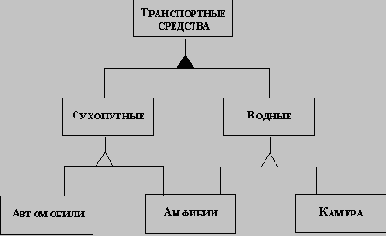 |
Рис. 4.20. Множественное наследование
Еще один пример множественного наследования приведен на следующем рисунке, где рассмотрено множественное наследование от непересекающихся классов.
В этом случае, который наиболее типичен для применения множественного наследования, свойства, унаследованные от разных предков, дополняют друг друга.
 |
В случае если множественное наследование не поддерживается языком программирования, выбранным для реализации, оно может быть заменено одним из следующих способов.
Использование вложенного простого наследования представлено на рисунке
Рис. 4.22. Реализация множественного наследования с помощью
вложенного простого наследования
Либо - делегирование с использованием агрегации ролей как показано на следующем рисунке. Делегированием называется механизм реализации, в котором объект, ответственный за операцию, пересылает (делегирует) эту операцию другому объекту; в объектно-ориентированных языках делегирование реализуется путем присоединения методов непосредственно к объектам, а не к классам.
В рассматриваемом примере операции классов оплата_труда и пенсионное_обеспечение делегируются объектам класса служащий, который можно рассматривать как результат агрегации классов оплата_труда и пенсионное_обеспечение.
Рис. 4.23. Реализация множественного наследования путем делегирования
с использованием агрегации ролей
Возможны и другие способы замены множественного наследования. Во всех случаях при выборе способа замены множественного наследования нужно руководствоваться следующими правилами:
· если подкласс имеет несколько суперклассов, каждый из которых одинаково существен, лучше всего использовать делегирование;
· если наиболее существенным является только один из суперклассов, а остальные не так важны, наилучшим способом является реализация множественного наследования через простое наследование и делегирование;
· если число возможных комбинаций групп наследуемых свойств невелико, можно использовать вложенное простое наследование; в случае большого числа комбинаций этот способ применять не следует;
· если один из суперклассов передает подклассу намного большее число свойств, чем остальные суперклассы, следует сохранить наследование по этому пути;
· если решено использовать вложенное простое наследование, то на первый уровень вложенности следует поместить наиболее существенный по передаче свойств суперкласс, затем наиболее существенный из оставшихся суперклассов и т.д.;
· следует избегать использования вложенного простого наследования, если это ведет к дублированию достаточно больших частей программы;
· следует помнить, что только вложенное простое наследование обеспечивает полную тождественность множественному наследованию.
Связь объектов с базой данных
В объектно-ориентированном проектировании мы имеем дело с множествами взаимосвязанных объектов. Каждый объект может рассматриваться как переменная или константа структурного типа (при таком рассмотрении методы, описываемые в объекте, трактуются как адреса функций, которые разрешено применять к этому объекту). Следовательно, множество объектов - это множество взаимосвязанных данных, т.е. нечто очень похожее на базу данных. Поэтому применение понятий баз данных часто оказывается полезным при объектно-ориентированном анализе и объектно-ориентированном проектировании прикладных программных систем. Рассмотрим на примерах некоторые особенности применения указанных понятий.
Метаданные
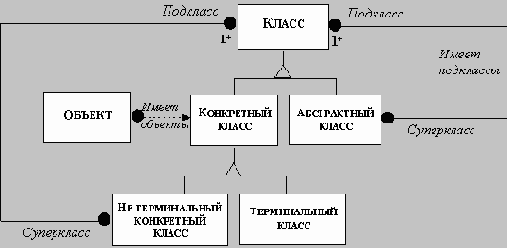 |
Рис. 4.24. Объектная модель, определяющая абстрактный
и конкретный классы
Класс описывает множество объектов - экземпляров этого класса. Объекты данного класса порождаются по описанию класса с помощью процесса, называемого тиражированием. Процесс тиражирования можно распространить и на другие случаи порождения экземпляров объектов по образцам. Рассмотрим, например, модели автомобилей, выпускаемых различными производителями. Класс модель_автомобиля имеет свои атрибуты (как, например, имя_модели, год_выпуска, базовая_цена) и зависимости (в частности, этот класс связан зависимостью с классом фирма). Но каждая модель_автомобиля может рассматриваться как метакласс, описывающий множество автомобилей, принадлежащих конкретным людям - их владельцам. Каждый класс автомобиль получает атрибуты от своего метакласса, но может иметь и собственные атрибуты (как, например, серийный_номер, цвет, комплектация). При этом гораздо удобнее и экономнее получать различные классы автомобиль тиражированием метакласса модель_автомобиля (схематически этот процесс тиражирования представлен на рисунке). Тиражирование изображается пунктирной стрелкой.
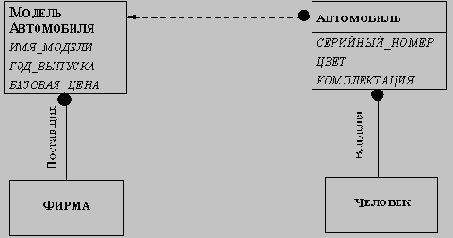 |
Использование возможных ключей
Возможным ключом (этот термин чаще употребляется в базах данных) называется минимальный набор атрибутов, который однозначно идентифицирует объект или связь. Связь - это экземпляр зависимости: каждая зависимость между классами порождает связи между объектами этих классов. Возможный ключ является минимальным набором атрибутов в том смысле, что если убрать из него хотя бы один из атрибутов, он уже не будет иметь различные значения для всех объектов или связей. Класс или зависимость могут иметь один или несколько возможных ключей, каждый из которых может представлять собой одну из комбинаций некоторого числа атрибутов. Одним из возможных ключей для любого класса всегда является идентификатор объекта. Одна или более комбинаций зависимых объектов являются возможными ключами для зависимости.
 |
Легко видеть, что ни какая из комбинаций элементов не определяет однозначно зависимости. Следовательно, единственным возможным ключом является тройка (проект, исполнитель, язык);
(студент,профессор,университет).
Ограничения
Ограничения - это функциональные зависимости между сущностями объектной модели. Под термином сущности подразумеваются объекты, классы, атрибуты, связи и зависимости. Ограничение сокращает количество возможных значений, которые может принимать некоторая сущность.
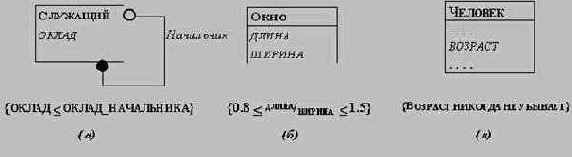
Рис. 4.27. Ограничения на объекты
На рисунке представлены ограничения, накладываемые на объекты:
(а) зарплата служащего не может превышать зарплаты его начальника (ограничение на значения одного атрибута разных объектов);
(б) никакое окно (на экране дисплея) не может иметь отношение длины к ширине, не лежащее в интервале от 0.8 до 1.5 (ограничение на значения разных атрибутов одного объекта);
(в) возраст человека не может убывать (ограничение на изменение значения атрибута во времени).
Ограничения указываются в фигурных скобках под изображением соответствующего класса на объектной диаграмме (они относятся ко всем объектам этого класса). Обычно ограничения могут быть выражены в виде логических функций (предикатов), которые и представляют их в программе. Ограничения дают один из критериев качества объектной модели: "хорошая" объектная модель обычно содержит много ограничений.
Производные объекты, связи и атрибуты
 |
Рис. 4.28. Производный атрибут
На рисунке показан производный атрибут возраст класса человек, возраст определяется как разность значений объекта текущая_дата (соответствующий класс также показан на рисунке) и атрибута дата_рождения объекта класса человек.
На следующем рисунке показано, что объект класса машина состоит из нескольких объектов класса узел, каждый из которых может состоять из объектов класса деталь. Каждый узел характеризуется смещением в системе координат, связанной с машиной, а каждая деталь характеризуется смещением в системе координат, связанной с узлом.
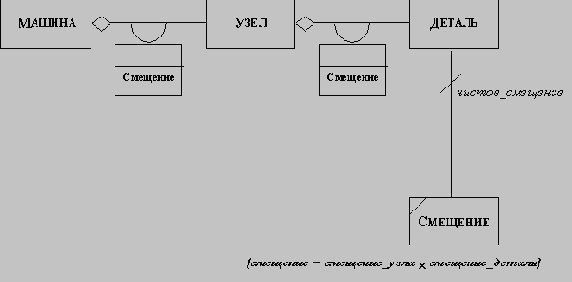
Для удобства можно для каждого объекта деталь определить систему координат, в которой координаты вычисляются с помощью координат объекта машина, смещения объекта узел и смещения объекта деталь. Эта система координат может быть представлена в производном классе смещение, который связан с каждым объектом деталь производной зависимостью чистое_смещение. Поскольку в реальном мире наблюдается большая избыточность, в объектные модели удобно вводить большое количество производных сущностей.
Рис. 4.29. Производный объект и производная зависимость
Гомоморфизмы
Гомоморфизм - это отображение между двумя зависимостями. Например, деталь, описанная в каталоге деталей автомобиля, может содержать в себе другие детали (составная деталь), также описанные в этом каталоге. Каждая позиция каталога снабжена номером модели; каждая деталь характеризуется своим серийным номером, причем каждая составная деталь содержит в себе соответствующие детали, также имеющие свои серийные номера.
На следующем рисунке показаны классы, соответствующие физическим деталям (класс деталь) и их описаниям в каталоге (класс модель_детали), а также зависимости между такими классами (поскольку речь идет о сложных деталях, эти зависимости являются агрегациями зависимости содержит). На рисунке показано отображение диаграмм объектных моделей, соответствующих физическим деталям, в диаграмму объектной модели, соответствующей каталогу. При этом следует иметь в виду, что поскольку разным физическим деталям одного вида (номенклатуры) соответствует одно описание в каталоге, рассматриваемое отображение как бы "склеивает" все диаграммы объектных моделей, соответствующих физическим деталям, в одну диаграмму объектной модели, соответствующей каталогу.
Описанное ото
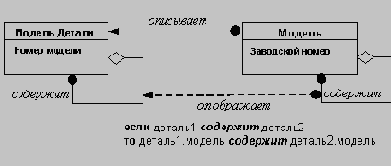 |
Рис. 4.30. Пример гомоморфизма
Общий случай гомоморфизма показан на рисунке. Гомоморфизм отображает связи, определяемые зависимостью u, в связи, определяемые зависимостью t, являясь отображением типа "много-в-один". Гоморфизмы обычно используются при изучении связей между метаобъектами и порождаемыми ими объектами (описание детали в каталоге может рассматриваться как метадеталь).
 |