Деревья
Данная лекция будет посвящена изучению и реализации на Прологе такой структуры данных, как деревья .
Начнем с маленького введения из теории графов , частным случаем которых являются деревья .
Обычно графом называют пару множеств: множество вершин и множество дуг (множество пар из множества вершин).Различают ориентированные и неориентированные графы . В ориентированном графе каждая дуга имеет направление (рассматриваются упорядоченные пары вершин). Графически обычно принято изображать вершины графа точками, а связи между ними - линиями, соединяющими точки-вершины.
Путем называется последовательность вершин, соединенных дугами. Для ориентированного графа направление пути должно совпадать с направлением каждой дуги, принадлежащей пути . Циклом называется путь , у которого совпадают начало и конец.
Две вершины ориентированного графа , соединенные дугой, называются отцом и сыном (или главной и подчиненной вершинами). Известно, что если граф не имеет циклов , то обязательно найдется хотя бы одна вершина, которая не является ничьим сыном. Такую вершину называют корневой. Если из одной вершины достижима другая, то первая называется предком , вторая - потомком .
Деревом называется граф , у которого одна вершина корневая, остальные вершины имеют только одного отца и все вершины являются потомками корневой вершины.
Листом дерева называется его вершина, не имеющая сыновей. Кроной дерева называется совокупность всех листьев . Высотой дерева называется наибольшая длина пути от корня к листу .
Нам будет удобно использовать следующее рекурсивное определение бинарного дерева : дерево либо пусто, либо состоит из корня , а также левого и правого поддеревьев, которые в свою очередь также являются деревьями .
В вершинах дерева может храниться информация любого типа. Для простоты в этой лекции будем считать, что в вершинах дерева располагаются целые числа. Тогда соответствующее этому определению описание альтернативного домена будет выглядеть следующим образом:
DOMAINS tree=empty;tr(i,tree,tree) /* дерево либо пусто, либо состоит из корня (целого числа), левого и правого поддеревьев, также являющихся деревьями */
Заметим, что идентификатор empty не является зарезервированным словом Пролога. Вместо него вполне можно употреблять какое-нибудь другое обозначение для пустого дерева . Например, можно использовать для обозначения дерева , не имеющего вершин, идентификатор nil, как в Лиспе, или void, как в Си. То же самое относится и к имени домена (и имени функтора): вместо tree (tr) можно использовать любой другой идентификатор.
Например, дерево
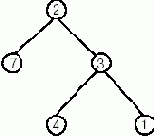
можно задать следующим образом:
tr(2,tr(7,empty, empty),tr(3,tree(4,empty,empty), tr(1,empty,empty))).
Теперь займемся написанием предикатов для реализации операций на бинарных деревьях .
Пример. Начнем с реализации предиката, который будет проверять принадлежность значения дереву . Предикат будет иметь два аргумента. Первым аргументом будет исходное значение, вторым - дерево , в котором мы ищем данное значение.
Следуя рекурсивному определению дерева , заметим, что некоторое значение принадлежит данному дереву , если оно либо содержится в корне дерева , либо принадлежит левому поддереву, либо принадлежит правому поддереву. Других вариантов нет.
Запишем это рассуждение на Прологе.
tree_member(X,tr(X,_,_)):-!. /* X - является корнем дерева */ tree_member(X,tr(_,L,_)):- tree_member(X,L),!. /* X принадлежит левому поддереву */ tree_member(X,tr(_,_,R)):- tree_member(X,R). /* X принадлежит правому поддереву */
Пример. Разработаем предикат, который будет заменять в дереве все вхождения одного значения на другое. У предиката будет четыре аргумента: три входных (значение, которое нужно заменять; значение, которым нужно заменять; исходное дерево ), четвертым - выходным - аргументом будет дерево , полученное в результате замены всех вхождений первого значения на второе.
Базис рекурсивного решения будет следующий. Из пустого дерева можно получить только пустое дерево . При этом абсолютно неважно, что на что мы заменяем. Шаг рекурсии зависит от того, находится ли заменяемое значение в корне дерева . Если находится, то нужно заменить корневое значение вторым значением, после чего перейти к замене первого значения на второе в левом и правом поддереве.
Если же в корне содержится значение, отличное от заменяемого, то оно должно остаться. Замену нужно произвести в левом и правом поддеревьях.
tree_replace(_,_,empty,empty). /* пустое дерево остается пустым деревом*/ tree_replace(X,Y,tr(X,L,R),tr(Y,L1,R1)):- /* корень содержит заменяемое значение X*/ !,tree_replace(X,Y,L,L1), /* L1 - результат замены в дереве L всех вхождений X на Y */ tree_replace(X,Y,R,R1). /* R1 - результат замены в дереве R всех вхождений X на Y */ tree_replace(X,Y,tr(K,L,R),tr(K,L1,R1)):- /* корень не содержит заменяемое значение X */ tree_replace(X,Y,L,L1), /* L1 - результат замены в дереве L всех вхождений X на Y */ tree_replace(X,Y,R,R1). /* R1 - результат замены в дереве R всех вхождений X на Y */
Пример. Напишем предикат, подсчитывающий общее количество вершин дерева . У него будет два параметра. Первый (входной) параметр - дерево , второй (выходной) - количество вершин в дереве .
Как всегда, пользуемся рекурсией. Базис: в пустом дереве количество вершин равно нулю. Шаг рекурсии: чтобы посчитать количество вершин дерева , нужно посчитать количество вершин в левом и правом поддереве, сложить полученные числа и добавить к результату единицу (посчитать корень дерева ).
Пишем:
tree_length (empty,0). /* В пустом дереве нет вершин */ tree_length(tr(_,L,R),N):- tree_length (L,N1), /* N1 - число вершин левого поддерева */ tree_length (R,N2), /* N2 - число вершин правого поддерева */ N=N1+N2+1. /* число вершин исходного дерева получается сложением N1, N2 и единицы */
Пример. Решим еще одну подобную задачу. Разработаем предикат, подсчитывающий не общее количество вершин дерева , а только количество листьев , т.е. вершин, не имеющих сыновей. Предикат будет иметь два параметра. Входной - исходное дерево , выходной - количество листьев дерева , находящегося в первом параметре.
Понятно, что, так как в пустом дереве нет вершин, в нем нет и вершин, являющихся листьями . Это первый базис рекурсии. Второй базис будет заключаться в очевидном факте, что дерево , состоящее из одной вершины, имеет ровно один лист .
Шаг: для того, чтобы посчитать количество листьев дерева , нужно просто сложить количество листьев в левом и правом поддереве.
Запишем:
tree_leaves(empty,0). /* в пустом дереве листьев нет */ tree_leaves(tr(_,empty,empty),1):-!. /* в дереве с одним корнем - один лист */ tree_leaves(tr(_,L,R),N):- tree_leaves(L,N1), /* N1 - количество листьев в левом поддереве */ tree_leaves(R,N2), /* N2 - количество листьев в правом поддереве */ N=N1+N2.
Пример. Создадим предикат, находящий сумму чисел, расположенных в вершинах дерева . Он будет иметь два аргумента. Первый - исходный список, второй - сумма чисел, находящихся в вершинах дерева , расположенного в первом аргументе.
Идея реализации будет очень простой и немного похожей на подсчет количества вершин. Базис рекурсии: сумма элементов пустого дерева равна нулю, потому что в пустом дереве нет элементов. Чтобы подсчитать сумму значений, находящихся в вершинах непустого дерева , нужно сложить сумму элементов, хранящихся в левом и правом поддереве, и не забыть добавить корневое значение.
На Прологе это записывается следующим образом:
tree_sum (empty,0). /* В пустом дереве вершин нет */ tree_sum(tr(X,L,R),N):- tree_sum (L,N1), /* N1 - сумма элементов левого поддерева */ tree_sum (R,N2), /* N2 - сумма элементов правого поддерева */ N=N1+N2+X. /* складываем N1, N2 и корневое значение */
Пример. Создадим предикат, позволяющий вычислить высоту дерева . Напомним, что высота дерева - это наибольшая длина пути от корня дерева до его листа . Предикат будет иметь два параметра. Первый (входной) - дерево , второй (выходной) - высота дерева , помещенного в первый параметр.
Базис рекурсии будет основан на том, что высота пустого дерева равна нулю. Шаг рекурсии - на том, что для подсчета высоты всего дерева нужно найти высоты левого и правого поддеревьев, взять их максимум и добавить единицу (учесть уровень, на котором находится корень дерева ). Предикат max (или max2), вычисляющий максимум из двух элементов, был разработан нами еще в третьей лекции.
Мы воспользуемся им при вычислении высоты дерева .
Получается следующее.
tree_height(empty,0). /* Высота пустого дерева равна нулю */ tree_height(tr(_,L,R),D) :- tree_height(L,D1), /* D1 - высота левого поддерева */ tree_height(R,D2), /* D2 - высота правого поддерева */ max(D1,D2,D_M), /* D_M - максимум из высот левого и правого поддеревьев */ D=D_M+1. /* D - высота дерева получается путем увеличения числа D_M на единицу*/
Существует особый вид бинарных деревьев - так называемые двоичные справочники . В двоичном справочнике все значения, входящие в левое поддерево, меньше значения, находящегося в корне , а все значения, расположенные в вершинах правого поддерева, больше корневого значения, а левое и правое поддеревья, в свою очередь, также являются двоичными справочниками . Такие деревья еще называют упорядоченными слева направо.
Пример. Усовершенствуем предикат tree_member для проверки принадлежности значения двоичному справочнику . Повысить эффективность этого предиката мы сможем, воспользовавшись тем, что в двоичном справочнике если искомое значение не совпадает с тем, которое хранится в корне , то его имеет смысл искать только в левом поддереве, если оно меньше корневого, и, соответственно, только в правом поддереве, если оно больше корневого значения.
Модифицированный предикат будет выглядеть следующим образом:
tree_member2(X,tr(X,_,_)):-!. /* X - корень дерева */ tree_member2(X,tr(K,L,_)):- X<K,!, tree_member2(X,L). /* X - принадлежит левому поддереву */ tree_member2(X,tr(K,_,R)):- X>K,!, tree_member2(X,R). /* X - принадлежит правому поддереву */
Пример. Создадим предикат, позволяющий добавить в двоичный справочник новое значение. При этом результирующее дерево должно получиться двоичным деревом . Предикат будет иметь три аргумента. Первым аргументом будет добавляемое значение, вторым - дерево , в которое нужно добавить данное значение, третьим - результат вставки первого аргумента во второй.
Решение, конечно, будет рекурсивным. На чем будет основано наше решение? Наша рекурсия будет основана на двух базисах и двух правилах.
Первый базис: если вставлять любое значение в пустое дерево , то в результате получим дерево , у которого левое и правое поддеревья - пустые, в корне записано добавляемое значение. Второй базис: если вставляемое значение совпадает со значением, находящимся в корневой вершине исходного дерева , то результат не будет отличаться от исходного дерева (в двоичном справочнике все элементы различны). Два правила рекурсии определяют, как нужно действовать, если исходное дерево непустое и его корневое значение отличается от вставляемого значения. В этой ситуации, если добавляемое значение меньше корневого, то его нужно добавить в левое поддерево, иначе - искать ему место в правом поддереве.
Запишем на Прологе реализацию этих рассуждений.
tree_insert(X,empty,tr(X,empty,empty)). /* вставляем X в пустое дерево, получаем дерево с X в корневой вершине,пустыми левым и правым поддеревьями */ tree_insert(X,tr(X,L,R),tr(X,L,R)):-!. /* вставляем X в дерево со значением X в корневой вершине, оставляем исходное дерево без изменений */ tree_insert(X,tr(K,L,R),tr(K,L1,R)):- X<K,!, tree_insert(X,L,L1). /* вставляем X в дерево с большим X элементом в корневой вершине, значит, нужно вставить X в левое поддерево исходногодерева */ tree_insert(X,tr(K,L,R),tr(K,L,R1)):- tree_insert(X,R,R1). /* вставляем X в дерево с меньшим X элементом в корневой вершине, значит, нужно вставить X в правое поддерево исходного дерева */
Можно обратить внимание на две особенности работы данного предиката. Во-первых, вершина, содержащая новое значение, будет добавлена в качестве нового листа дерева . Это следует из первого предложения нашей процедуры. Во-вторых, если добавляемое значение уже содержится в нашем двоичном справочнике , то оно не будет добавлено, дерево останется прежним, без изменений. Это следует из второго предложения процедуры, описывающей наш предикат.
Пример. Создадим предикат, генерирующий дерево , которое является двоичным справочником и состоит из заданного количества вершин, в которых будут размещены случайные целые числа.
Как можно было заметить, записывать деревья вручную довольно сложно. Этот предикат позволит нам автоматически создавать деревья с нужным количеством элементов. В дальнейшем он пригодится для проверки других предикатов, обрабатывающих деревья .
Предикат будет иметь два аргумента. Первый, входной, будет задавать требуемое количество элементов. Второй, выходной, будет равен сгенерированному дереву .
Решение будет, естественно, рекурсивным. Рекурсия по количеству вершин дерева . Базис рекурсии: нулевое количество вершин имеется только в пустом дереве . Если количество вершин должно быть больше нуля, то нужно (с помощью встроенного предиката random, рассмотренного в пятой лекции) сгенерировать случайное значение, построить дерево , имеющее вершин на одну меньше, чем итоговое дерево , вставить случайное значение в построенное дерево , воспользовавшись созданным перед этим предикатом tree_insert.
tree_gen(0,empty):-!. /* ноль вершин соответствует пустому дереву */ tree_gen (N,T):- random(100,X), /* X - случайное число из промежутка [0,100) */ N1= N-1, tree_gen (N1,T1), /* T1 - дерево, имеющее N-1 вершин */ tree_insert(X,T1,T). /* вставляем X в дерево T1 */
Обратите внимание на то, что, на самом деле, дерево , сгенерированное этим предикатом, не обязательно будет иметь столько вершин, сколько было указано в первом параметре. Если вспомнить реализацию предиката tree_insert, то можно обратить внимание на то, что в ситуации, когда вставляемое значение уже содержится в двоичном справочнике , оно не будет добавлено в дерево . Т.е. всякий раз, когда случайное число, генерируемое встроенным предикатом random, уже содержится в некоторой вершине дерева , оно не попадет в дерево , и, следовательно, итоговое дерево будет содержать на одну вершину меньше. Если во время построения двоичного справочника такая ситуация будет возникать несколько раз, то в итоговом дереве будет на соответствующее количество вершин меньше, чем можно было ожидать.
Если нам обязательно нужно по какой-то причине получить дерево , содержащее ровно столько вершин, сколько было указано в первом параметре, нужно модифицировать этот предикат.
Это можно сделать несколькими способами.
Первый вариант: можно модифицировать предикат, осуществляющий добавление значения в двоичный справочник так, чтобы в случае, когда вставляемое значение совпадало с корневым значением, генерировалось новое случайное число, после чего еще раз осуществлялась попытка вставки вновь сгенерированного значения в дерево .
Другой вариант: можно поменять местами вызов предикатов random и tree_gen и после генерации случайного числа проверять с помощью предиката tree_member2, не содержится ли это значение в уже построенном дереве . Если его там нет, значит, его можно спокойно вставить в двоичный справочник с помощью предиката tree_insert. Если же это значение уже содержится в одной из вершин дерева , значит, нужно сгенерировать новое случайное число, после чего опять проверить его наличие и т.д.
Надо заметить, что если задать требуемое количество вершин дерева , заведомо большее, чем первый аргумент предиката random (количество различных случайных чисел, генерируемых этим предикатом), мы получим зацикливание. Например, в приведенном выше примере вызывается предикат random(100,X). Этот предикат будет возвращать целые случайные числа из промежутка от 0 до 99. Различных чисел из этого промежутка всего сто. Следовательно, и справочник , генерируемый с помощью нашего предиката, может содержать не более ста вершин.
Эту проблему можно обойти, если сделать первый аргумент предиката random зависящим от заказанного числа вершин дерева (заведомо больше).
Пример. Далее логично заняться предикатом, который будет удалять заданное значение из двоичного справочника . У него будет три параметра. Два входных (удаляемое значение и исходное дерево ) и результат удаления первого параметра из второго.
Реализовать этот предикат оказывается не так просто, как хотелось бы. Без особых проблем можно написать базисы рекурсии для случая, когда удаляемое значение является корневым, а левое или правое поддерево пусты. В этом случае результатом будет, соответственно, правое или левое поддерево.
Шаг рекурсии для случая, когда значение, содержащееся в корне дерева , отличается от удаляемого значения, также реализуется без проблем. Нам нужно выяснить, меньше удаляемое значение корневого или больше. В первом случае перейти к удалению данного значения из левого поддерева, во втором - к удалению этого значения из правого поддерева. Проблема возникает, когда нам нужно удалить корневую вершину в дереве , у которого и левое, и правое поддеревья не пусты.
Есть несколько вариантов разрешения возникшей проблемы. Один из них заключается в следующем. Можно удалить из правого поддерева минимальный элемент (или из левого дерева максимальный) и заменить им значение, находящееся в корне . Так как любой элемент правого поддерева больше любого элемента левого поддерева, дерево , получившееся в результате такого удаления и замены корневого значения, останется двоичным справочником .
Для удаления из двоичного справочника вершины, содержащей минимальный элемент, нам понадобится отдельный предикат. Его реализация будет состоять из двух предложений. Первое будет задавать базис рекурсии и срабатывать в случае, когда левое поддерево пусто. В этой ситуации минимальным элементом дерева является значение, находящееся в корне , потому что, по определению двоичного справочника , все значения, находящиеся в вершинах правого поддерева, больше значения, находящегося в корневой вершине. И, значит, нам достаточно удалить корень , а результатом будет правое поддерево.
Второе предложение будет задавать шаг рекурсии и выполняться, когда левое поддерево не пусто. В этой ситуации минимальный элемент находится в левом поддереве и его нужно оттуда удалить. Так как минимальное значение нам потребуется, чтобы вставить его в корневую вершину, у этого предиката будет не два аргумента, как можно было бы ожидать, а три. Третий (выходной) аргумент будет нужен нам для возвращения минимального значения.
Запишем оба эти предиката.
Начнем со вспомогательного предиката, удаляющего минимальный элемент двоичного справочника .
tree_del_min(tr(X,empty,R), R, X). /* Если левое поддерево пусто, то минимальный элемент - корень, а дерево без минимального элемента - это правое поддерево.*/ tree_del_min(tr(K,L,R), tr(K,L1,R), X):- tree_del_min(L, L1, X). /* Левое поддерево не пусто, значит, оно содержит минимальное значениевсего дерева, которое нужно удалить */
Основной предикат, выполняющий удаление вершины из дерева , будет выглядеть следующим образом.
tree_delete(X,tr(X,empty,R), R):-!. /* X совпадает с корневым значением исходного дерева, левое поддерево пусто */ tree_delete (X,tr(X,L,empty), L):-!. /* X совпадает с корневым значением исходного дерева, правое поддерево пусто */ tree_delete (X,tr(X,L,R), tr(Y,L,R1)):- tree_del_min(R,R1, Y). /* X совпадает с корневым значением исходного дерева, причем ни левое, ни правое поддеревья не пусты */ tree_delete (X,tr(K,L,R), tr(K,L1,R)):- X<K,!, tree_delete (X,L,L1). /* X меньше корневого значения дерева */ tree_delete (X,tr(K,L,R), tr(K,L,R1)):- tree_delete (X,R,R1). /* X больше корневого значения дерева */
Пример. Создадим предикат, который будет преобразовывать произвольный список в двоичный справочник . Предикат будет иметь два аргумента. Первый (входной) - произвольный список, второй (выходной) - двоичный справочник , построенный из элементов первого аргумента.
Будем переводить список в дерево рекурсивно. То, что из элементов пустого списка можно построить лишь пустое дерево , даст нам базис рекурсии. Шаг рекурсии будет основан на той идее, что для того, чтобы перевести непустой список в дерево , нужно перевести в дерево его хвост, после чего вставить голову в полученное дерево .
То же самое на Прологе:
list_tree([],empty). /* Пустому списку соответствует пустое дерево */ list_tree([H|T],Tr):- list_tree(T,Tr1), /* Tr1 - дерево, построенное из элементов хвоста исходного списка */ tree_insert(H,Tr1,Tr). /* Tr - дерево, полученное в результате вставки головы списка в дерево Tr1 */
Пример. Создадим обратный предикат, который будет "сворачивать" двоичный справочник в список с сохранением порядка элементов.
Предикат будет иметь два аргумента. Первый (входной) - произвольный двоичный справочник , второй (выходной) - список, построенный из элементов первого аргумента.
tree_list(empty,[]). /* Пустому дереву соответствует пустой список */ tree_list(tr(K,L,R),S):- tree_list(L,T_L), /* T_L - список, построенный из элементов левого поддерева */ tree_list(R,T_R), /* T_L - список, построенный из элементов правого поддерева */ conc(T_L,[K|T_R],S). /* S - список, полученный соединением списков T_L и [K|T_R] */
Заметьте, что, используя предикаты list_tree и tree_list, можно отсортировать список, состоящий из различных элементов, переписав его в двоичный справочник , а затем переписав двоичный справочник обратно в список.
Запишем предикат, выполняющий сортировку списка, переписывая его в двоичный список и обратно.
sort_listT(L,L_S):- list_tree(L,T), /* T- двоичный справочник, построенный из элементов исходного списка L */ tree_list(T,L_S). /* L_S - список, построенный из элементов двоичного справочника T */
Так как в двоичном справочнике все элементы различны, при переписывании списка в двоичный справочник и обратно повторяющиеся элементы будут из него удалены. Неизменным останется количество элементов списка, только если все его элементы были различны.